This AI Paper from the National University of Singapore Introduces a Defense Against Adversarial Attacks on LLMs Utilizing Self-Evaluation

Ensuring the safety of Large Language Models (LLMs) has become a pressing concern in the ocean of a huge number of existing LLMs serving multiple domains. Despite the implementation of training methods like Reinforcement Learning from Human Feedback (RLHF) and the development of inference-time guardrails, many adversarial attacks have demonstrated the ability to bypass these defenses. This has sparked a surge in research focused on developing robust defense mechanisms and methods for detecting harmful outputs. However, existing approaches face several challenges. Some rely on computationally expensive algorithms, others require fine-tuning of models, and some depend on proprietary APIs, such as OpenAI’s content moderation service. These limitations highlight the need for more efficient and accessible solutions to enhance the safety and reliability of LLM outputs.
Researchers have made various attempts to tackle the challenges of ensuring safe LLM outputs and detecting harmful content. These efforts span multiple areas, including harmful text classification, adversarial attacks, LLM defenses, and self-evaluation techniques.
In the realm of harmful text classification, approaches range from traditional methods using specifically trained models to more recent techniques utilising LLMs’ instruction-following abilities. Adversarial attacks have also been extensively studied, with methods like Universal Transferable Attacks, DAN, and AutoDAN emerging as significant threats. The discovery of “glitch tokens” has further highlighted vulnerabilities in LLMs.
To counter these threats, researchers have developed various defense mechanisms. These include fine-tuned models like Llama-Guard and LlamaGuard 2, which act as guardrails for model inputs and outputs. Other proposed defenses involve filtering techniques, inference-time guardrails, and smoothing methods. Also, self-evaluation has shown promise in improving model performance across various aspects, including the identification of harmful content.
Researchers from the National University of Singapore propose a robust defense against adversarial attacks on LLMs using self-evaluation. This method employs pre-trained models to evaluate inputs and outputs of a generator model, eliminating the need for fine-tuning and reducing implementation costs. The approach significantly decreases attack success rates on both open and closed-source LLMs, outperforming Llama-Guard2 and common content moderation APIs. Comprehensive analysis, including attempts to attack the evaluator in various settings, demonstrates the method’s superior resilience compared to existing techniques. This innovative strategy marks a significant advancement in enhancing LLM security without the computational burden of model fine-tuning.
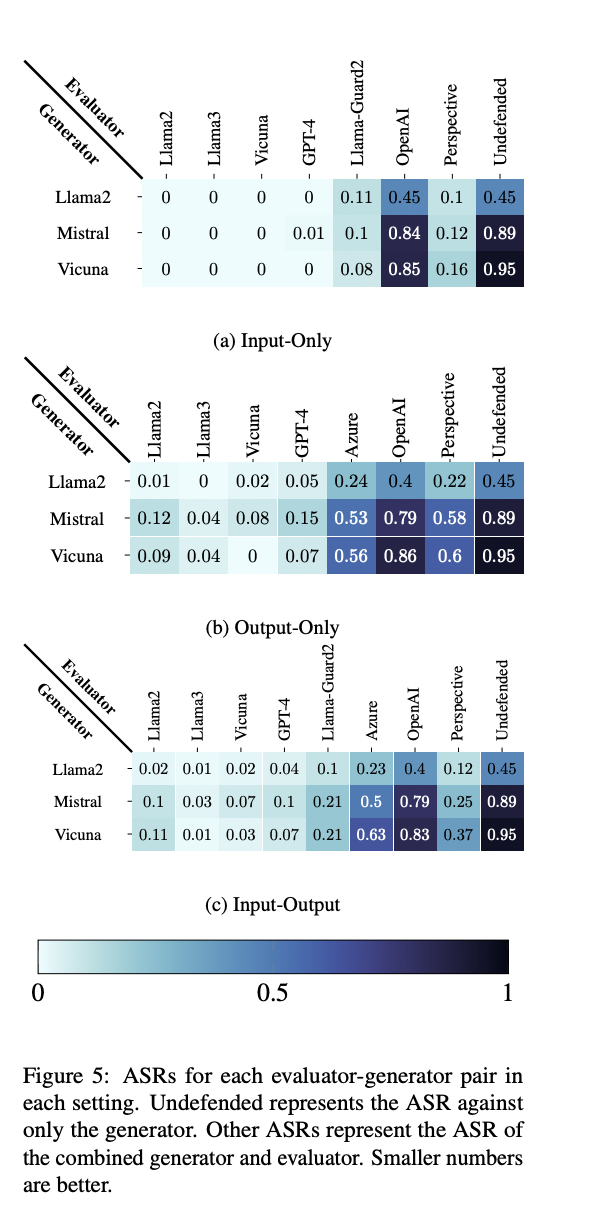
The researchers propose a defense mechanism against adversarial attacks on LLMs using self-evaluation. This approach employs an evaluator model (E) to assess the safety of inputs and outputs from a generator model (G). The defense is implemented in three settings: Input-Only, where E evaluates only the user input; Output-Only, where E assesses G’s response; and Input-Output, where E examines both input and output. Each setting offers different trade-offs between security, computational cost, and vulnerability to attacks. The Input-Only defense is faster and cheaper but may miss context-dependent harmful content. The Output-Only defense potentially reduces exposure to user attacks but may incur additional costs. The Input-Output defense provides the most context for safety evaluation but is the most computationally expensive.
The proposed self-evaluation defense demonstrates significant effectiveness against adversarial attacks on LLMs. Without defense, all tested generators show high vulnerability, with attack success rates (ASRs) ranging from 45.0% to 95.0%. However, the implementation of the defense drastically reduces ASRs to near 0.0% across all evaluators, generators, and settings, outperforming existing evaluation APIs and Llama-Guard2. Open-source models used as evaluators perform comparably or better than GPT-4 in most scenarios, highlighting the accessibility of this defense. The method also proves resilient to over-refusal issues, maintaining high response rates for safe inputs. These results underscore the robustness and efficiency of the self-evaluation approach in enhancing LLM security against adversarial attacks.
This research demonstrates the effectiveness of self-evaluation as a robust defense mechanism for LLMs against adversarial attacks. Pre-trained LLMs show high accuracy in identifying attacked inputs and outputs, making this approach both powerful and easy to implement. While potential attacks against this defense exist, self-evaluation remains the strongest current defense against unsafe inputs, even when under attack. Importantly, it maintains model performance without increasing vulnerability. Unlike existing defenses such as Llama-Guard and defense APIs, which falter when classifying samples with adversarial suffixes, self-evaluation remains resilient. The method’s ease of implementation, compatibility with small, low-cost models, and strong defensive capabilities make it a significant contribution to enhancing LLM safety, robustness, and alignment in practical applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.








