Google AI Introduces DataGemma: A Set of Open Models that Utilize Data Commons through Retrieval Interleaved Generation (RIG) and Retrieval Augmented Generation (RAG)
Google has introduced a groundbreaking innovation called DataGemma, designed to tackle one of modern artificial intelligence’s most significant problems: hallucinations in large language models (LLMs). Hallucinations occur when AI confidently generates information that is either incorrect or fabricated. These inaccuracies can undermine AI’s utility, especially for research, policy-making, or other important decision-making processes. In response, Google’s DataGemma aims to ground LLMs in real-world, statistical data by leveraging the extensive resources available through its Data Commons.
They have introduced two specific variants designed to enhance the performance of LLMs further: DataGemma-RAG-27B-IT and DataGemma-RIG-27B-IT. These models represent cutting-edge advancements in both Retrieval-Augmented Generation (RAG) and Retrieval-Interleaved Generation (RIG) methodologies. The RAG-27B-IT variant leverages Google’s extensive Data Commons to incorporate rich, context-driven information into its outputs, making it ideal for tasks that need deep understanding and detailed analysis of complex data. On the other hand, the RIG-27B-IT model focuses on integrating real-time retrieval from trusted sources to fact-check and validate statistical information dynamically, ensuring accuracy in responses. These models are tailored for tasks that demand high precision and reasoning, making them highly suitable for research, policy-making, and business analytics domains.
The Rise of Large Language Models and Hallucination Problems
LLMs, the engines behind generative AI, are becoming increasingly sophisticated. They can process enormous amounts of text, create summaries, suggest creative outputs, and even draft code. However, one of the critical shortcomings of these models is their occasional tendency to present incorrect information as fact. This phenomenon, known as hallucination, has raised concerns about the reliability & trustworthiness of AI-generated content. To address these challenges, Google has made significant research efforts to reduce hallucinations. These advancements culminate in the release of DataGemma, an open model specifically designed to anchor LLMs in the vast reservoir of real-world statistical data available in Google’s Data Commons.
Data Commons: The Bedrock of Factual Data
Data Commons is at the heart of DataGemma’s mission, a comprehensive repository of publicly available, reliable data points. This knowledge graph contains over 240 billion data points across many statistical variables drawn from trusted sources such as the United Nations, the WHO, the Centers for Disease Control and Prevention, and various national census bureaus. By consolidating data from these authoritative organizations into one platform, Google empowers researchers, policymakers, and developers with a powerful tool for deriving accurate insights.
The scale and richness of the Data Commons make it an indispensable asset for any AI model that seeks to improve the accuracy and relevance of its outputs. Data Commons covers various topics, from public health and economics to environmental data and demographic trends. Users can interact with this vast dataset through a natural language interface, asking questions such as how income levels correlate with health outcomes in specific regions or which countries have made the most significant strides in expanding access to renewable energy.
The Dual Approach of DataGemma: RIG and RAG Methodologies
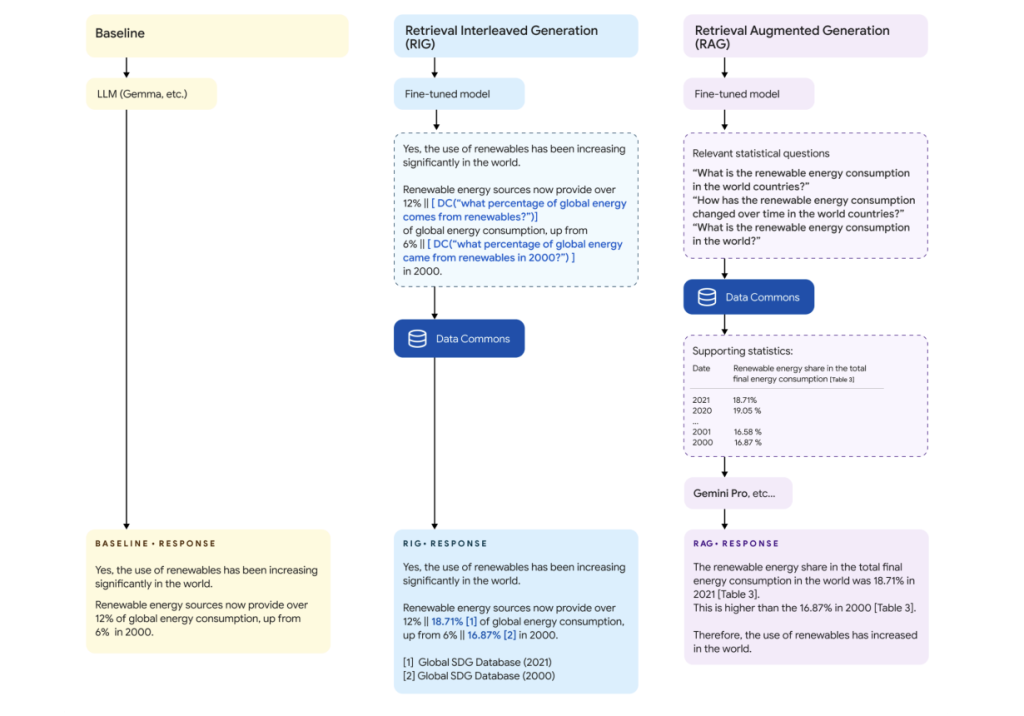
Google’s innovative DataGemma model employs two distinct approaches to enhancing the accuracy and factuality of LLMs: Retrieval-Interleaved Generation (RIG) and Retrieval-Augmented Generation (RAG). Each method has unique strengths.
The RIG methodology builds on existing AI research by integrating proactive querying of trusted data sources within the model’s generation process. Specifically, when DataGemma is tasked with generating a response that involves statistical or factual data, it cross-references the relevant data within the Data Commons repository. This methodology ensures that the model’s outputs are grounded in real-world data and fact-checked against authoritative sources.
For example, in response to a query about the global increase in renewable energy usage, DataGemma’s RIG approach would pull statistical data directly from Data Commons, ensuring that the answer is based on reliable, real-time information.
On the other hand, the RAG methodology expands the scope of what language models can do by incorporating relevant contextual information beyond their training data. DataGemma leverages the capabilities of the Gemini model, particularly its long context window, to retrieve essential data before generating its output. This method ensures that the model’s responses are more comprehensive, informative, and less hallucination-prone.
When a query is posed, the RAG method first retrieves pertinent statistical data from Data Commons before producing a response, thus ensuring that the answer is accurate and enriched with detailed context. This is particularly useful for complex questions that require more than a straightforward factual answer, such as understanding trends in global environmental policies or analyzing the socioeconomic impacts of a particular event.
Initial Results and Promising Future
Although the RIG and RAG methodologies are still in their early stages, preliminary research suggests promising improvements in the accuracy of LLMs when handling numerical facts. By reducing the risk of hallucinations, DataGemma holds significant potential for various applications, from academic research to business decision-making. Google is optimistic that the enhanced factual accuracy achieved through DataGemma will make AI-powered tools more reliable, trustworthy, and indispensable for anyone seeking informed, data-driven decisions.
Google’s research and development team continues to refine RIG and RAG, with plans to scale up these efforts and subject them to more rigorous testing. The ultimate goal is to integrate these improved functionalities into the Gemma and Gemini models through a phased approach. For now, Google has made DataGemma available to researchers and developers, providing access to the models and quick-start notebooks for both the RIG and RAG methodologies.
Broader Implications for AI’s Role in Society
The release of DataGemma marks a significant step forward in the journey to make LLMs more reliable and grounded in factual data. As generative AI becomes increasingly integrated into various sectors, ranging from education and healthcare to governance and environmental policy, addressing hallucinations is crucial to ensuring that AI empowers users with accurate information.
Google’s commitment to making DataGemma an open model reflects its broader vision of fostering collaboration and innovation in the AI community. By making this technology available to developers, researchers, and policymakers, Google aims to drive the adoption of data-grounding techniques that enhance AI’s trustworthiness. This initiative advances the field of AI and underscores the importance of fact-based decision-making in today’s data-driven world.
In conclusion, DataGemma is an innovative leap in addressing AI hallucinations by grounding LLMs in the vast, authoritative datasets of Google’s Data Commons. By combining the RIG and RAG methodologies, Google has created a robust tool that enhances the accuracy and reliability of AI-generated content. This release is a significant step toward ensuring that AI becomes a trusted partner in research, decision-making, and knowledge discovery, all while empowering individuals and organizations to make more informed choices based on real-world data.
Check out the Details, Paper, RAG Gemma, and RIG Gemma. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group.
📨 If you like our work, you will love our Newsletter..
Don’t Forget to join our 50k+ ML SubReddit
⏩ ⏩ FREE AI WEBINAR: ‘SAM 2 for Video: How to Fine-tune On Your Data’ (Wed, Sep 25, 4:00 AM – 4:45 AM EST)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.









