SynSUM: A Synthetic Benchmark for Integrating Clinical Notes with Structured Data
[ad_1]
Electronic Health Records (EHRs) present a wealth of information, combining structured tabular data and unstructured clinical notes. This valuable resource forms the foundation for training clinical decision support systems and automating diagnosis and treatment planning processes. While large language models (LLMs) can utilize unstructured text, they lack interpretability, an important factor in high-risk clinical applications. Moreover, feature-based models are better for their robustness, but these cannot directly process unstructured text. This creates a significant challenge in utilizing the full potential of EHRs for clinical decision-making, highlighting the need for effective clinical information extraction (CIE) methods to bridge the gap between unstructured data and interpretable models.
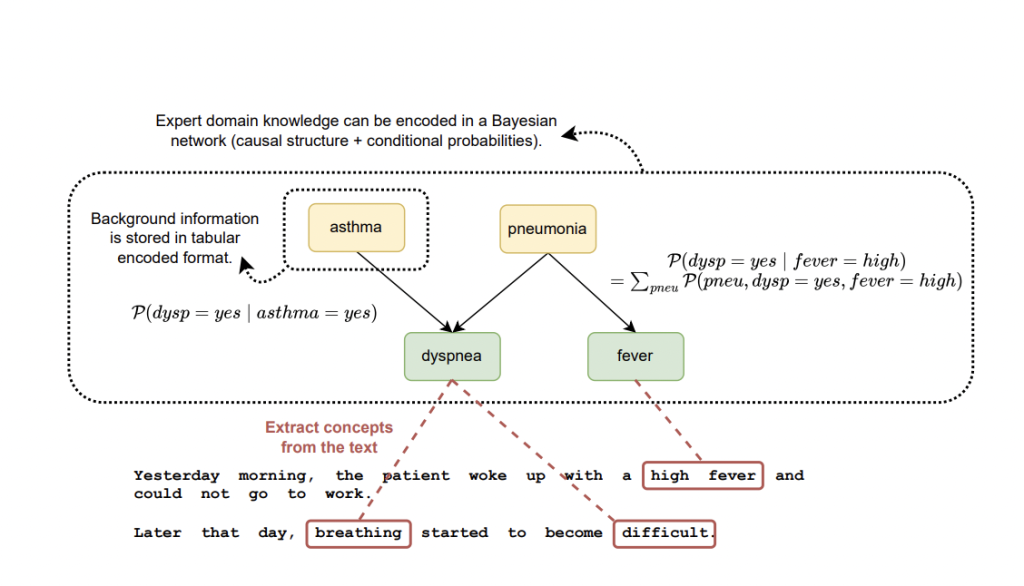
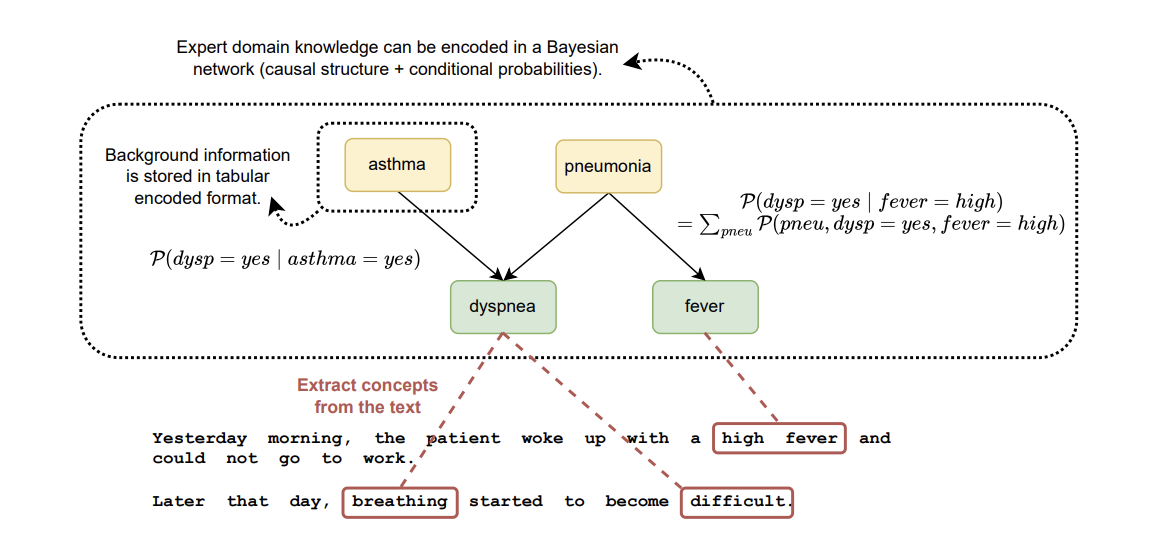
Existing methods do not fully utilize available medical knowledge to close this gap. Two additional sources of information, are tabular features already encoded in EHRs, and medical domain knowledge structured as a Bayesian network, and capable of enhancing CIE. This helps connect encoded background information with concepts extracted from the text. However, a suitable clinical dataset containing both tabular data and unstructured text is needed to implement this idea. While open-source datasets like MIMIC-III and MIMIC-IV exist, they present challenges such as complexity, billing-driven tabular features, and inconsistent links between features and text concepts.
Researchers from IDLab, Department of Information Technology at Ghent University – imec Ghent, Belgium, and the Department of Public Health and Primary Care at Ghent University Ghent, Belgium have proposed the SynSUM benchmark, which is a synthetic dataset that links unstructured clinical notes to structured background variables. This dataset contains 10,000 artificial patient records in the domain of respiratory diseases, containing both tabular variables and related clinical notes. SynSUM provides research on clinical information extraction with tabular background variables, linked through domain knowledge to concepts of interest in the text, and supports research in clinical reasoning automation
The proposed method, SynSUM utilizes four distinct approaches to predict symptoms from clinical data:
BN-tab: A Bayesian network with a predefined causal structure, using maximum likelihood estimation to learn parameters from training data.
XGBoost-tab: An XGBoost classifier trained for each symptom under three different evidence settings, with hyperparameters optimized through cross-validation.
Neural-text: A neural classifier that processes only the text input, using sentence embeddings from the BioLORD model to predict symptom probabilities.
Neural-text-tab: An extension of the neural-text approach that uses tabular variables with text embeddings, using separate classifiers for each symptom.
The methods are evaluated using an 8000/2000 train-test split, with cross-validation for hyperparameter tuning. They reported F1-scores for each symptom prediction, using a 0.5 probability threshold for classification. Results show that text-based methods (neural-text and neural-text-tab) outperformed tabular-only approaches (BN-tab and XGBoost-tab). Symptoms such as dyspnea, cough, and nasal congestion are easily predictable, compared to pain and fever. A performance gap is observed between normal and compact notes, attributed to the latter’s higher complexity. Also, the concatenation of embeddings slightly outperformed mean embeddings, indicating complementary information in different note sections.
In summary, researchers have introduced the SynSUM dataset that offers multiple potential applications in healthcare research. Its main purpose is to enhance clinical information extraction techniques to combine tabular background variables. The dataset’s unique structure, utilizing structured and unstructured data with known relationships, makes it valuable for various research areas at the intersection of tabular data and text in healthcare. This versatility positions SynSUM as a valuable resource for enhancing multiple facets of medical informatics and data science in healthcare settings. Future work contains the use of domain knowledge to link tabular features with textual concepts for more accurate extraction.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
⏩ ⏩ FREE AI WEBINAR: ‘SAM 2 for Video: How to Fine-tune On Your Data’ (Wed, Sep 25, 4:00 AM – 4:45 AM EST)

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
[ad_2]
Source link