Salesforce AI Research Introduce xGen-MM (BLIP-3): A Scalable AI Framework for Advancing Large Multimodal Models with Enhanced Training and Performance Capabilities
[ad_1]
Large Multimodal Models (LMMs) are rapidly advancing, driven by the need to develop artificial intelligence systems capable of processing and generating content across multiple modalities, such as text and images. These models are particularly valuable in tasks that require a deep integration of visual and linguistic information, such as image captioning, visual question answering, and multimodal language understanding. As AI technologies evolve, effectively combining these different data types has become increasingly critical for improving AI’s performance in complex, real-world scenarios.
Despite significant progress in developing LMMs, several challenges persist, particularly in the accessibility and scale of resources available to the research community. The primary issue is the limited access to large-scale, high-quality datasets and the complex training methodologies required to create robust models. Open-source initiatives often need to catch up to proprietary models due to these constraints, which hinders the ability of researchers to replicate, understand, and build upon existing models. This disparity slows innovation and limits the potential applications of LMMs in various fields. Addressing these challenges is crucial for democratizing access to advanced AI technologies and enabling broader participation in their development.
Current approaches to building LMMs typically involve sophisticated architectures that effectively integrate vision and language modalities. For instance, cross-attention mechanisms are commonly used to link these two data types, as seen in models like Flamingo and LLaVA. These methods rely heavily on large-scale pre-training, followed by fine-tuning specific tasks to enhance model performance. However, despite their success, these models need to be improved, particularly regarding data scale, diversity, and the complexity of their training processes. For example, the BLIP-2 model, although a pioneering effort, needs help with the scale and diversity of its training data, which hampers its ability to achieve competitive performance compared to more modern LMMs. The intricate Q-Former architecture used in BLIP-2 adds further challenges in scaling up training processes, making it difficult for researchers to work with larger datasets.
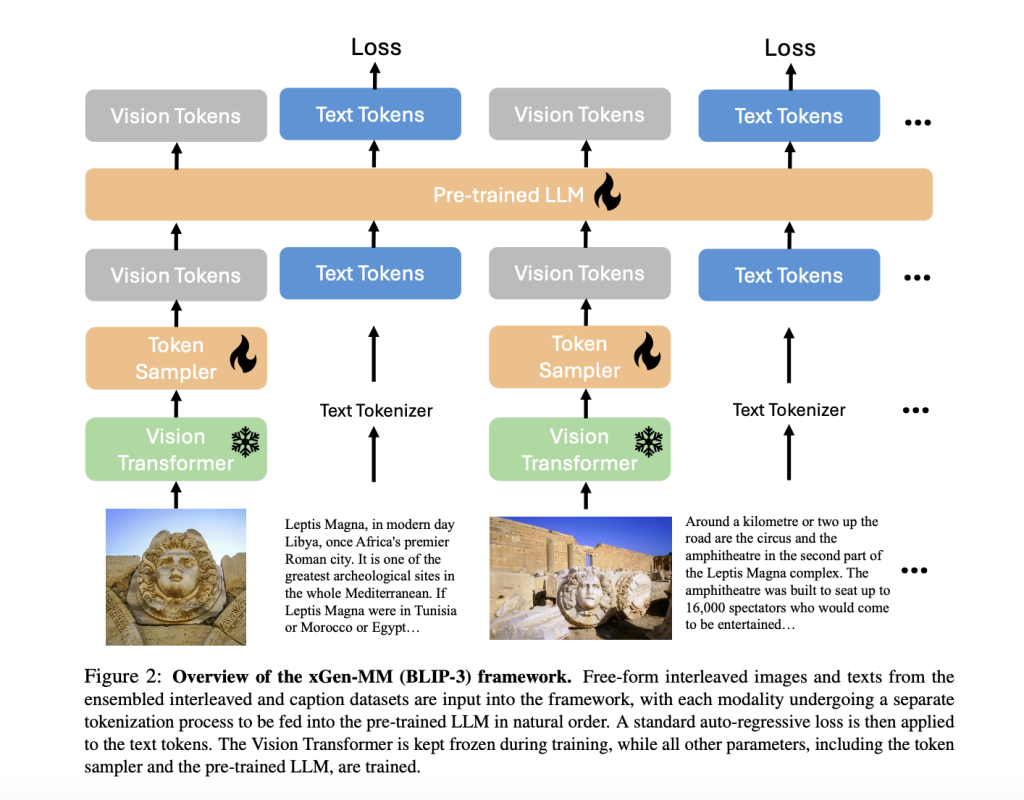
Researchers from Salesforce AI Research and the University of Washington have introduced the xGen-MM (BLIP-3) framework as an innovative solution designed to enhance the scalability and accessibility of LMMs. The xGen-MM framework builds upon previous efforts but introduces several key improvements to overcome earlier models’ limitations. The framework utilizes an ensemble of multimodal interleaved datasets, curated caption datasets, and publicly available datasets to create a robust training environment. A significant innovation in xGen-MM is the replacement of the Q-Former layers with a more scalable vision token sampler, specifically a perceiver resampler. This change simplifies the training process by unifying the training objectives into a single loss function at each stage, streamlining the model development process and making it more accessible for large-scale training.

The xGen-MM (BLIP-3) framework incorporates several advanced technologies to improve the efficiency and effectiveness of multimodal training. Central to the framework is a pre-trained large language model (phi3-mini) paired with a vision token sampler. This combination allows the model to handle free-form interleaved images and texts, which is essential for tasks requiring a deep understanding of multimodal content. The training process includes a dynamic high-resolution image encoding strategy, enabling the model to effectively process images at varying resolutions. This strategy involves patch-wise encoding of images, preserving their resolution while reducing the sequence length of vision tokens. This method enhances the model’s ability to interpret text-rich images and significantly reduces computational requirements, making the model more scalable and efficient for large-scale applications.

The performance of the xGen-MM (BLIP-3) models has been rigorously evaluated across several multimodal benchmarks, demonstrating impressive results. For instance, the instruction-tuned models showed outstanding performance in visual question answering (VQA) and optical character recognition (OCR) tasks. Specifically, xGen-MM significantly outperformed comparable models in tasks such as TextVQA and COCO captioning, achieving scores of 66.9 and 90.6 in 8-shot evaluations, respectively. Introducing safety-tuned models has further enhanced the reliability of these LMMs by reducing harmful behaviors, such as hallucinations while maintaining high accuracy in complex multimodal tasks. The models also excelled in tasks requiring high-resolution image processing, showcasing the effectiveness of the dynamic high-resolution encoding strategy.

In conclusion, the xGen-MM (BLIP-3) framework offers a robust solution for developing high-performance LMMs by addressing critical challenges related to data accessibility and training scalability. Using an ensemble of curated datasets and innovative training methodologies has enabled the xGen-MM models to set new benchmarks in multimodal performance. The framework’s ability to integrate complex visual and textual data efficiently and accurately makes it a valuable tool for researchers and practitioners.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.

[ad_2]
Source link







