OpenAI Researchers Propose a Multi-Step Reinforcement Learning Approach to Improve LLM Red Teaming
[ad_1]
As the use of large language models (LLMs) becomes increasingly prevalent across real-world applications, concerns about their vulnerabilities grow accordingly. Despite their capabilities, LLMs are still susceptible to various types of adversarial attacks, including those that generate toxic content, reveal private information, or allow for prompt injections. These vulnerabilities pose significant ethical concerns regarding bias, misinformation, potential privacy violations, and system abuse. The need for an effective strategy to address these issues is pressing. Traditionally, red teaming—a process that involves stress-testing AI systems by simulating attacks—has been effective for vulnerability detection. However, past approaches to automated red teaming have often struggled to balance the diversity of generated attacks and their effectiveness, limiting the robustness of the models.
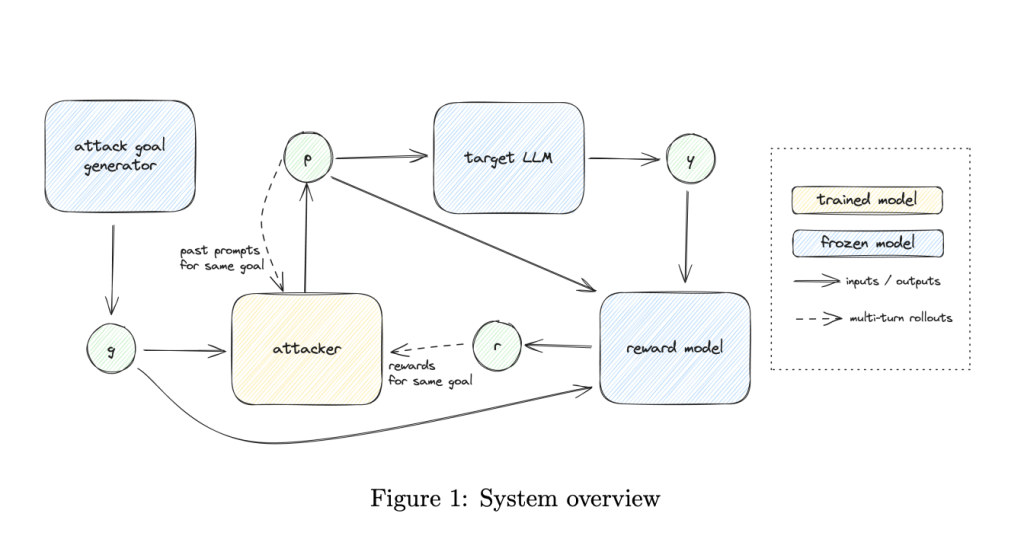
To address these challenges, OpenAI researchers propose an approach to automated red teaming that incorporates both diversity and effectiveness in the attacks generated. This is achieved by decomposing the red teaming process into two distinct steps. The first step involves generating diverse attacker goals, while the second step trains a reinforcement learning (RL) attacker to effectively meet these goals. The proposed method uses multi-step reinforcement learning (multi-step RL) and automated reward generation. This approach involves leveraging large language models to generate attacker goals and utilizing rule-based rewards (RBRs) and custom diversity measures to guide RL training. By rewarding an RL-based attacker for being both effective and distinct from its past attempts, the method ensures greater diversity and effectiveness of the attacks.

Technical Details
The research team describes the decomposition of the red teaming system into generating goals and training attacks as a means to simplify the process while achieving robust results. For generating goals, the authors utilize both few-shot prompting of a language model and existing datasets of past attacks. These goals serve as a diverse foundation, giving the RL-based attacker specific but varied directions to optimize for. The core of the RL-based attacker training uses a targeted rule-based reward function for each example, ensuring that each attack aligns with a specific adversarial goal. Moreover, to prevent the RL attacker from converging on similar attack strategies, a diversity reward is implemented that focuses on stylistic differences in generated prompts. Multi-step RL allows the attacker to iterate on its own attacks and be rewarded for successfully generating new and varied types of attacks—leading to a more comprehensive red teaming system. This process helps identify the model’s vulnerabilities while ensuring that the diversity of adversarial examples closely mirrors those that could be encountered in real-world situations.
The significance of this red teaming approach lies in its ability to address both the effectiveness and diversity of attacks, a duality that has been a long-standing challenge in automated adversarial generation. By using multi-step RL and automated rewards, the approach allows the generated attacks to be diverse and relevant. The authors demonstrated their approach on two key applications: prompt injection attacks and “jailbreaking” attacks that elicit unsafe responses. In both scenarios, the multi-step RL-based attacker showed improved effectiveness and diversity of attacks compared to previous methods. Specifically, the indirect prompt injection, which can trick a model into generating unintended behavior, achieved a high attack success rate and was notably more varied in style compared to one-shot prompting methods. Overall, the proposed method was able to generate attacks with an attack success rate of up to 50%, while achieving substantially higher diversity metrics than prior approaches. This combination of automated reward generation and reinforcement learning provides a nuanced mechanism for probing model robustness and ultimately improving the LLM’s defenses against real-world threats.

Conclusion
The proposed red teaming approach offers a direction for automated adversarial testing of LLMs, addressing previous limitations involving trade-offs between attack diversity and effectiveness. By leveraging both automated goal generation and multi-step RL, this methodology allows for a more detailed exploration of the vulnerabilities present in LLMs, ultimately helping to create safer and more robust models. While the results presented are promising, there are still limitations and areas for further research, particularly in refining the automated rewards and optimizing training stability. Nevertheless, the combination of RL with rule-based rewards and diversity-focused training marks an important step in adversarial testing, providing a model that can better respond to the evolving nature of attacks.
Check out the Paper here. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
[ad_2]
Source link