MDAgents: A Dynamic Multi-Agent Framework for Enhanced Medical Decision-Making with Large Language Models
Foundation models hold promise in medicine, especially in assisting complex tasks like Medical Decision-Making (MDM). MDM is a nuanced process requiring clinicians to analyze diverse data sources—like imaging, electronic health records, and genetic information—while adapting to new medical research. LLMs could support MDM by synthesizing clinical data and enabling probabilistic and causal reasoning. However, applying LLMs in healthcare remains challenging due to the need for adaptable, multi-tiered approaches. Although multi-agent LLMs show potential in other fields, their current design lacks integration with the collaborative, tiered decision-making essential for effective clinical use.
LLMs are increasingly applied to medical tasks, such as answering medical exam questions, predicting clinical risks, diagnosing, generating reports, and creating psychiatric evaluations. Improvements in medical LLMs primarily stem from training with specialized data or using inference-time methods like prompt engineering and Retrieval Augmented Generation (RAG). General-purpose models, like GPT-4, perform well on medical benchmarks through advanced prompts. Multi-agent frameworks enhance accuracy, with agents collaborating or debating to solve complex tasks. However, existing static frameworks can limit performance across diverse tasks, so a dynamic, multi-agent approach may better support complex medical decision-making.
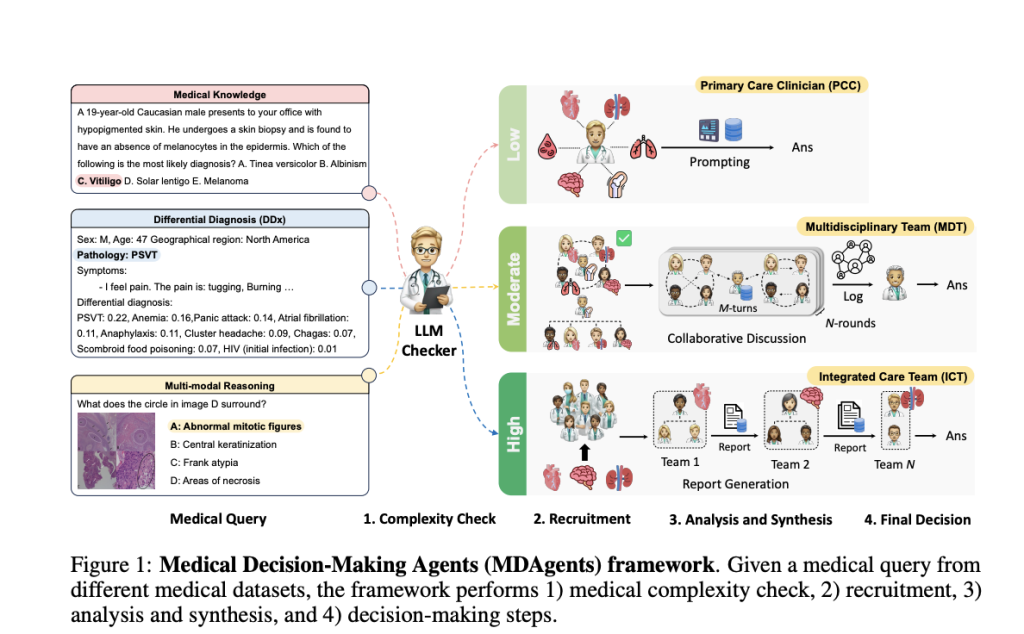
MIT, Google Research, and Seoul National University Hospital developed Medical Decision-making Agents (MDAgents), a multi-agent framework designed to dynamically assign collaboration among LLMs based on medical task complexity, mimicking real-world medical decision-making. MDAgents adaptively choose solo or team-based collaboration tailored to specific tasks, performing well across various medical benchmarks. It surpassed prior methods in 7 out of 10 benchmarks, achieving up to a 4.2% improvement in accuracy. Key steps include assessing task complexity, selecting appropriate agents, and synthesizing responses, with group reviews improving accuracy by 11.8%. MDAgents also balance performance with efficiency by adjusting agent usage.
The MDAgents framework is structured around four key stages in medical decision-making. It begins by assessing the complexity of a medical query—classifying it as low, moderate, or high. Based on this assessment, appropriate experts are recruited: a single clinician for simpler cases or a multi-disciplinary team for more complex ones. The analysis stage then uses different approaches based on case complexity, ranging from individual evaluations to collaborative discussions. Finally, the system synthesizes all insights to form a conclusive decision, with accurate results indicating MDAgents’ effectiveness compared to single-agent and other multi-agent setups across various medical benchmarks.
The study assesses the framework and baseline models across various medical benchmarks under Solo, Group, and Adaptive conditions, showing notable robustness and efficiency. The Adaptive method, MDAgents, effectively adjusts inference based on task complexity and consistently outperforms other setups in seven of ten benchmarks. Researchers who test datasets like MedQA and Path-VQA find that adaptive complexity selection enhances decision accuracy. By incorporating MedRAG and a moderator’s review, accuracy improves by up to 11.8%. Additionally, the framework’s resilience across parameter changes, including temperature adjustments, highlights its adaptability for complex medical decision-making tasks.
In conclusion, the study introduces MDAgents, a framework enhancing the role of LLMs in medical decision-making by structuring their collaboration based on task complexity. Inspired by clinical consultation dynamics, MDAgents assign LLMs to either solo or group roles as needed, aiming to improve diagnostic accuracy. Testing across ten medical benchmarks shows that MDAgents outperform other methods on seven tasks, with up to a 4.2% accuracy gain (p < 0.05). Ablation studies reveal that combining moderator reviews and external medical knowledge in group settings boosts accuracy by an average of 11.8%, underscoring MDAgents’ potential in clinical diagnosis.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.









