MatMamba: A New State Space Model that Builds upon Mamba2 by Integrating a Matryoshka-Style Nested Structure
[ad_1]
Scaling state-of-the-art models for real-world deployment often requires training different model sizes to adapt to various computing environments. However, training multiple versions independently is computationally expensive and leads to inefficiencies in deployment when intermediate-sized models are optimal. Current solutions like model compression and distillation have limitations, often requiring additional data and retraining, which may degrade model accuracy. A new research paper addresses these challenges by enabling adaptive inference for large-scale state space models (SSMs), ensuring efficient deployment across different computational setups without significant accuracy losses.
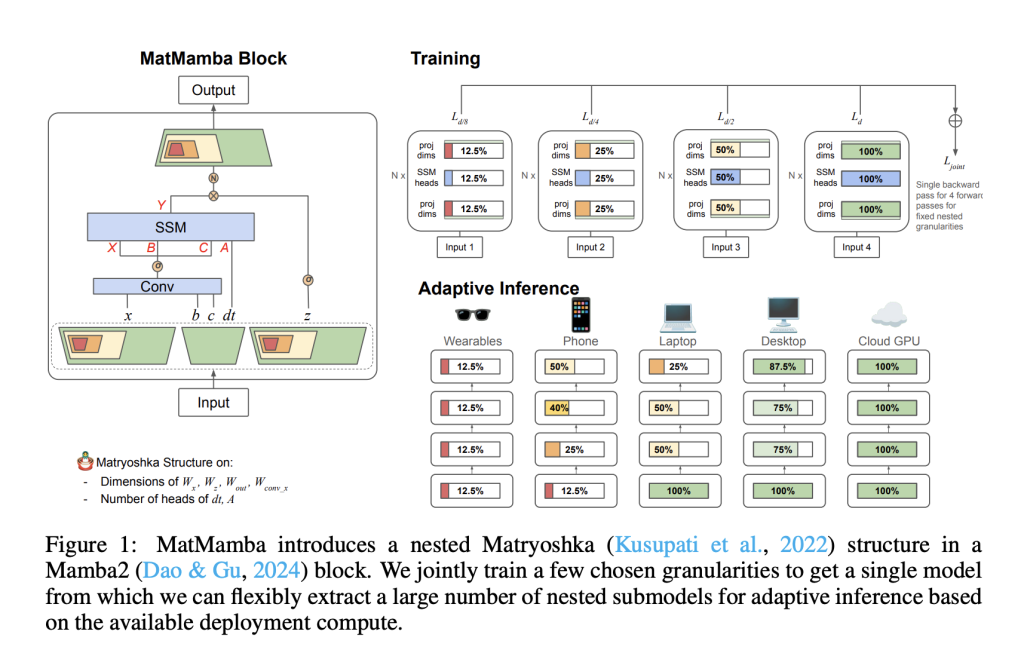
Researchers from Scaled Foundations and the University of Washington introduce MatMamba, a new state space model that builds upon Mamba2 by integrating a Matryoshka-style nested structure. The concept is inspired by Matryoshka Representation Learning, which has demonstrated success in enabling different granularities of submodels within a single universal model. The main contribution of MatMamba is the creation of an architecture that allows a single large model to have multiple smaller submodels “nested” within it. This provides the flexibility of deploying models of various sizes without needing separate independent training. By leveraging nested dimensions, the MatMamba model achieves adaptive inference, which is especially useful for large-scale tasks with variable compute resources. The researchers trained MatMamba models with parameter sizes ranging from 35 million to 1.4 billion, demonstrating its viability for diverse deployment scenarios.
Structurally, MatMamba is designed to incorporate multiple nested Mamba2 blocks, each representing a different model granularity. A MatMamba block consists of a series of Mamba2 blocks arranged in a nested form such that smaller sub-blocks are present within larger blocks, allowing for flexibility during inference. The entire model is trained by optimizing all the granularities simultaneously, using multiple forward passes followed by a single backward pass to update parameters. This design approach not only enables adaptive inference but also ensures that the different granularities within the model share similar metrics, preserving the metric space across different submodels. Importantly, MatMamba can be applied to any type of model, including encoder-decoder frameworks and multiple modalities, making it versatile for language, vision, sound, and other sequence-processing tasks.
The researchers conducted extensive experiments, showcasing the effectiveness of MatMamba for both vision and language tasks. For vision, they used MatMamba-Vision models on ImageNet and found that these models scaled comparably to traditional Mamba2-based models while maintaining efficient inference at different resolutions. The flexibility of MatMamba enabled adaptive image retrieval, where smaller submodels could be used to encode queries, significantly reducing compute costs while maintaining accuracy. For language modeling, the MatMamba-LM models were trained with different parameter sizes, from 130 million to 1.4 billion, on the FineWeb dataset. The results showed that the nested models matched the performance of independently trained Mamba2 baselines, demonstrating consistent scaling and effective parameter reduction. Additionally, the adaptive inference capabilities of MatMamba allowed researchers to flexibly extract a combinatorially large number of submodels, which performed well across different tasks, spanning the accuracy vs. compute Pareto curve.
In conclusion, MatMamba represents a significant advancement in enabling adaptive inference for state space models. By combining Matryoshka-style learning with the efficient architecture of Mamba2; it offers a practical solution for deploying large-scale models flexibly without compromising accuracy. The ability to derive multiple nested submodels from a single set of weights has broad implications for deploying AI systems in dynamic computing environments. MatMamba provides new possibilities, such as speculative decoding with a smaller draft model and larger verifier model, input-adaptive submodel selection, and hybrid cloud-edge inference, all while leveraging the strengths of state space modeling.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17, 2024] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
[ad_2]
Source link