Lotus: A Diffusion-based Visual Foundation Model for Dense Geometry Prediction
[ad_1]
Dense geometry prediction in computer vision involves estimating properties like depth and surface normals for each pixel in an image. Accurate geometry prediction is critical for applications such as robotics, autonomous driving, and augmented reality, but current methods often require extensive training on labeled datasets and struggle to generalize across diverse tasks.
Existing methods for dense geometry prediction typically rely on supervised learning approaches that use convolutional neural networks (CNNs) or transformer architectures. These methods require large amounts of labeled data and often fail to perform well in zero-shot scenarios, where models are expected to generalize to new tasks without task-specific training. Moreover, most current models are designed for specific geometry prediction tasks and lack versatility in adapting to other related tasks.
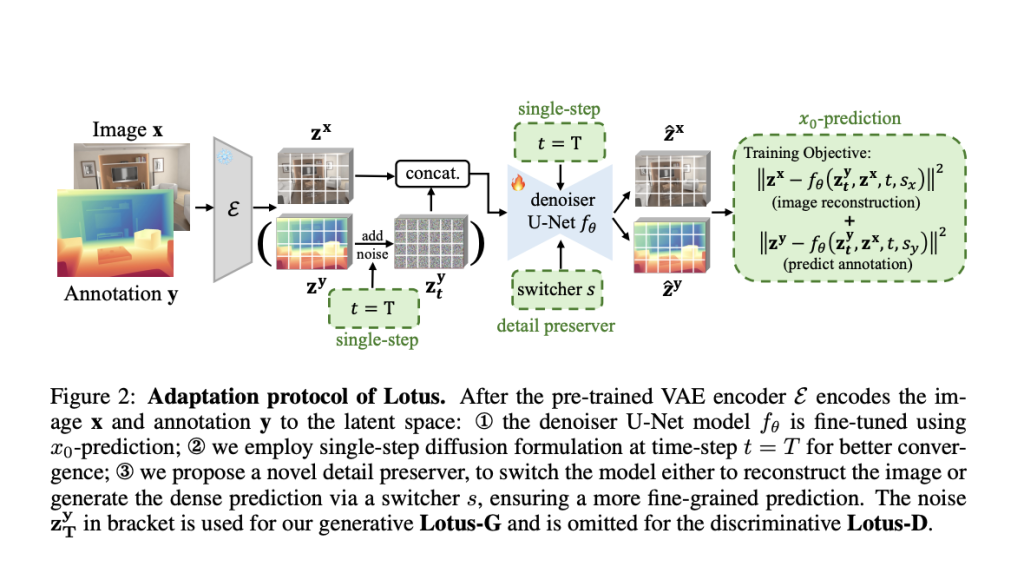
To overcome these challenges, a team of researchers from HKUST(GZ), University of Adelaide, Huawei Noah’s Ark Lab, and HKU have introduced Lotus, a novel diffusion-based visual foundation model that aims to improve high-quality dense geometry prediction. Lotus is designed to handle diverse geometry perception tasks, such as Zero-Shot Depth and Normal estimation, using a unified approach. Unlike traditional models that rely on task-specific architectures, Lotus leverages diffusion processes to generate visual predictions, making it more flexible and capable of adapting to various dense prediction tasks without requiring extensive retraining.
Lotus is a diffusion-based visual foundation model, which means it uses a probabilistic diffusion process to generate detailed geometry predictions from visual inputs. In this model, images are transformed through a series of noise-added stages, and then gradually denoised to generate predictions for depth and surface normals. This approach allows Lotus to capture rich geometric details that are often overlooked by conventional CNN-based models.
The researchers designed Lotus to function in a zero-shot setting, allowing it to generalize to new geometry prediction tasks without the need for task-specific training. This makes Lotus a versatile tool for dense visual prediction, suitable for various applications where adaptability is key. In experiments, Lotus achieved state-of-the-art (SoTA) performance on two major geometry perception tasks: Zero-Shot Depth and Normal estimation. The model outperformed existing baselines, demonstrating its effectiveness in producing high-quality geometry predictions even in challenging, unseen scenarios.
In addition to achieving high performance, Lotus also comes with user-friendly tools to explore its capabilities. The authors have released two Gradio applications on Hugging Face Spaces, providing an interactive way for users to experiment with Lotus and see how it performs on real-world data.
Overall, Lotus represents a significant advancement in the field of dense geometry prediction. By leveraging a diffusion-based approach, it effectively overcomes the limitations of traditional methods, providing a flexible and powerful solution for diverse visual prediction tasks. Its impressive zero-shot performance highlights its potential as a visual foundation model for a wide range of applications.
Check out the Paper and Demo. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
[ad_2]
Source link








