Latent Action Pretraining for General Action models (LAPA): An Unsupervised Method for Pretraining Vision-Language-Action (VLA) Models without Ground-Truth Robot Action Labels
[ad_1]
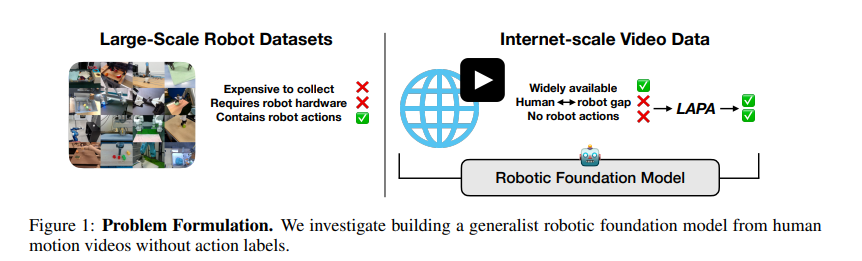
Vision-Language-Action Models (VLA) for robotics are trained by combining large language models with vision encoders and then fine-tuning them on various robot datasets; this allows generalization to new instructions, unseen objects, and distribution shifts. However, various real-world robot datasets mostly require human control, which makes scaling difficult. On the other hand, Internet video data offers many examples of human behavior and physical interactions at scale, presenting a better approach to overcome the limitations of small, specialized robotic datasets. Also, learning from internet videos is a bit tough for two reasons: most online videos don’t have clear labels for their corresponding actions, and the situations shown in web videos are very different from the environments that robots work in.
Vision-Language Models (VLMs), trained on extensive internet-scale datasets encompassing text, image, and video, have demonstrated understanding and generating text-to-print and multimodal data. Recently, incorporating auxiliary objectives, such as visual traces, language reasoning paths, or constructing a conversational-style instruction dataset using robot trajectory data during VLA training has improved performance. However, these methods still heavily rely on labeled action data, which limits the scalability of developing general VLAs since they will be bounded by the amount of robotic data made available through human teleoperation. Training Robot Policies from Videos contain rich information about dynamics and behavior, which can be potentially beneficial for robot learning. Some recent works explore the benefits of video generative models pre-trained on human videos for downstream robotic tasks. Another line of work aims to learn useful information from human videos by learning from interactions, affordances, or visual traces extracted from human videos. Another line of work aims to learn robot manipulation policies by retargeting human motions to robot motions. These works rely on off-the-shelf models such as hand pose estimators or motion capture systems to retarget the human motions directly to robot motions. Existing methods for training robots are either task-specific or require perfectly combined human-robot data, limiting their generalization of it. Some approaches label large datasets with small amounts of action-labeled data to train robots, but they still have issues with scaling according to the need.
The researchers from the KAIST, University of Washington, Microsoft Research, NVIDIA, and Allen Institute for AI proposed Latent Action Pre Training for General Action models (LAPA), an unsupervised method that leverages internet-scale videos without robot action labels. They proposed this method to learn from internet-scale videos that do not have robot action labels. LAPA involves training an action quantization model leveraging VQ-VAE-based objective to learn discrete latent actions between image frames, then pre-train a latent VLA model to predict these latent actions from observations and task descriptions, and finally fine-tune the VLA on small-scale robot manipulation data to map from latent to robot actions. Experimental results demonstrate that the method proposed significantly outperforms existing techniques that train robot manipulation policies from large-scale videos. Furthermore, it outperforms the state-of-the-art VLA model trained with robotic action labels on real-world manipulation tasks that require language conditioning, generalization to unseen objects, and semantic generalization to unseen instructions.
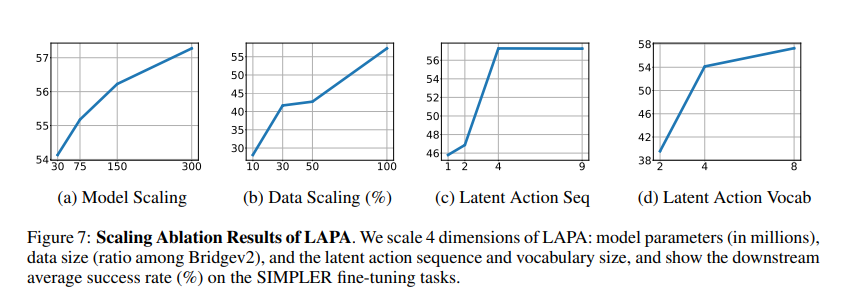
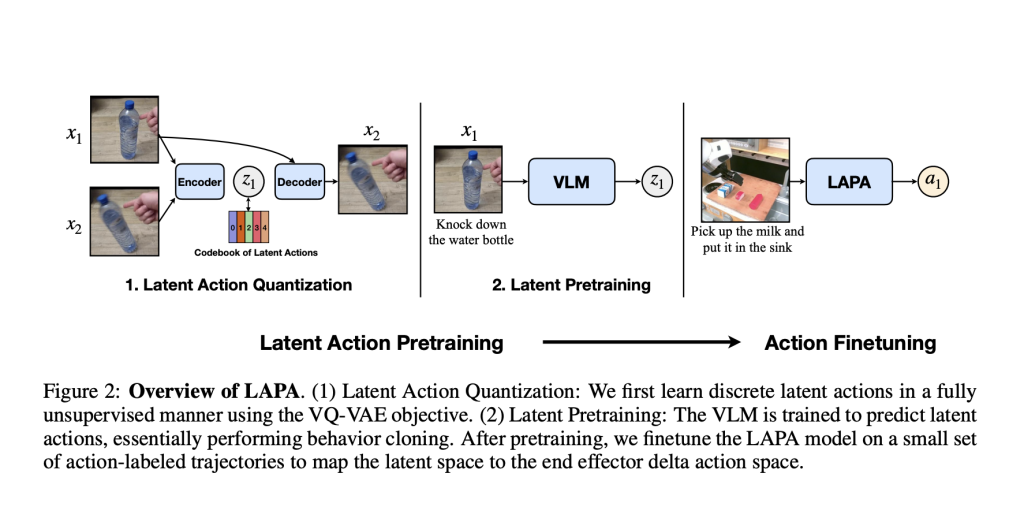
LAPA consists of two pretraining stages followed by fine-tuning to connect latent actions to real robotic actions. In the first stage, a VQ-VAE-based method is used to break down actions into smaller, basic parts without needing any set categories for those actions. The second stage involves behavior cloning, where a Vision-Language Model predicts latent actions from video observations and task descriptions. The model is then fine-tuned on a small robot manipulation dataset to learn the mapping from latent to robotic actions. LAPA, which stands for the proposed Vision-Language-Action (VLA) model, outperforms the previous best model, OPENVLA, despite being trained only on human manipulation videos. It shows better performance than larger robotic datasets like Bridgev2 and is 30-40 times more efficient in pretraining, using only 272 H100 hours compared to OPENVLA’s 21,500 A100-hours. LAPA’s performance benefits from larger models and datasets, but there are diminishing returns at certain scales. Additionally, it aligns well with real movements, proving effective in tasks involving human manipulation. Moreover, simulations demonstrate LAPA’s ability to plan robot actions based on simple instructions, highlighting its potential for use in complex robotic systems. LAPA significantly improves robotic performance in tasks, both in simulations and real-world scenarios, compared to previous methods that also rely on unlabeled video. It even outperforms the current best model that uses labeled actions by 6.22%, and it is over 30 times more efficient in pretraining.
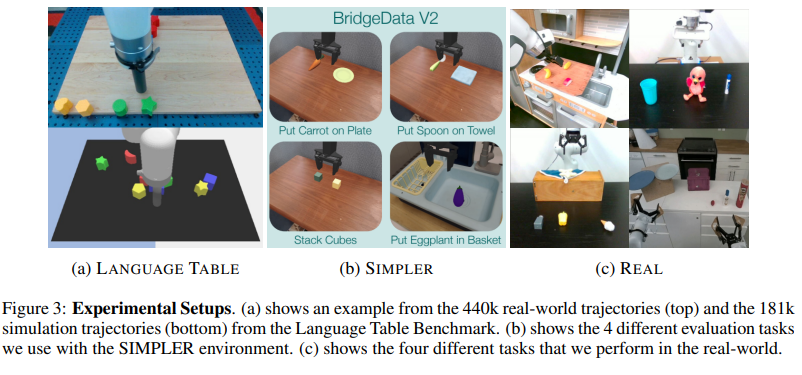
In conclusion, LAPA is a scalable pre-training method for building VLAs using actionless videos. Across three benchmarks spanning both simulation and real-world robot experiments, it showed that this method significantly improves transfer to downstream tasks compared to existing approaches. It also presented a state-of-the-art VLA model that surpasses current models trained on 970K action-labeled trajectories. Furthermore, it demonstrated that LAPA could be applied purely to human manipulation videos, where explicit action information is absent, and the embodiment gap is substantial.
Despite these unique features, LAPA underperforms compared to action pretraining when it comes to fine-grained motion generation tasks like grasping. Increasing the latent action generation space could help address this issue. Second, similar to prior VLAs, LAPA also encounters latency challenges during real-time inference. Adopting a hierarchical architecture, where a smaller head predicts actions at a higher frequency, could potentially reduce latency and improve fine-grained motion generation. LAPA shows camera movements but hasn’t been tested beyond manipulation videos, like in self-driving cars or navigation. This work can be expanded to create scalable robot models and support future research.
Check out the Paper, Model Card on HuggingFace, and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Nazmi Syed is a consulting intern at MarktechPost and is pursuing a Bachelor of Science degree at the Indian Institute of Technology (IIT) Kharagpur. She has a deep passion for Data Science and actively explores the wide-ranging applications of artificial intelligence across various industries. Fascinated by technological advancements, Nazmi is committed to understanding and implementing cutting-edge innovations in real-world contexts.
[ad_2]
Source link