Google Deepmind Researchers Introduce Jumprelu Sparse Autoencoders: Achieving State-of-the-Art Reconstruction Fidelity
[ad_1]
The Sparse Autoencoder (SAE) is a type of neural network designed to efficiently learn sparse representations of data. The Sparse Autoencoder (SAE) neural network efficiently learns sparse data representations. Sparse Autoencoders (SAEs) enforce sparsity to capture only the most important data characteristics for fast feature learning. Sparsity helps reduce dimensionality, simplifying complex datasets while keeping crucial information. SAEs reduce overfitting and improve generalization to unseen information by limiting active neurons.
Language model (LM) activations can be approximated and sparsely decomposed into linear components using a large dictionary of fundamental “feature” directions. This is how SAEs function. To be considered good, a decomposition must be sparse, meaning that reconstructing any given activation requires very few dictionary elements, and faithful, meaning that the approximation error between the original activation and recombining its SAE decomposition is “small” in an appropriate sense. These two goals are inherently at odds with one another because, with most SAE training methods and fixed dictionary sizes, increasing sparsity usually decreases reconstruction fidelity.
Google DeepMind researchers have introduced a novel concept, JumpReLU SAEs. This is a significant departure from the original ReLU-based SAE design. In JumpReLU SAEs, the SAE encoder uses a JumpReLU activation function instead of ReLU. This innovative approach eliminates pre-activations below a certain positive threshold, opening up new possibilities in the field of SAE design. The JumpReLU activation function is a modified version of the ReLU function, which introduces a jump in the function at the threshold, effectively reducing the number of active neurons and improving the generalization of the model.
They find that the expected loss’s derivative is typically non-zero, even though it’s expressed in terms of the probability densities of the feature activation distribution that need to be estimated. This is significant because, even though such a loss function is a piecewise constant concerning the threshold, it gives zero gradients to train this parameter.
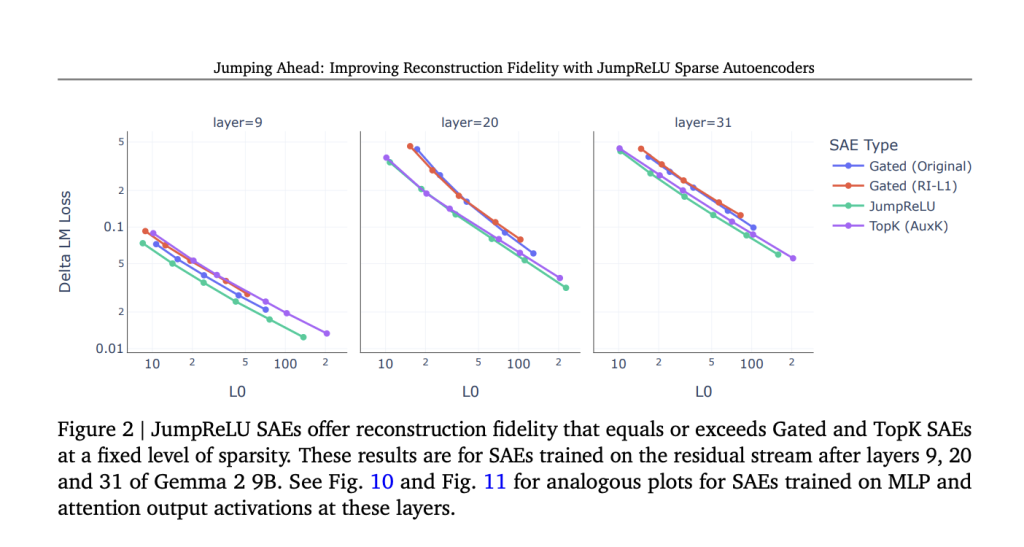
The researchers provide an effective way to estimate the gradient of the predicted loss using straight-through estimators, which enables JumpReLU SAEs to be trained using standard gradient-based approaches. Using activations from the attention output, MLP output, and the Gemma 2 9B residual stream over many layers, they assess JumpReLU, Gated, and TopK SAEs. They discover that, regardless of the sparsity level, JumpReLU SAEs reliably outperform Gated SAEs regarding reconstruction faithfulness.
When compared to TopK SAEs, JumpReLU SAEs stand out for their efficiency. They provide reconstructions that are not just competitive, but often superior. Unlike TopK, which requires a partial sort, JumpReLU SAEs, similar to simple ReLU SAEs, only need one forward and backward pass during training. This efficiency makes them a compelling choice for SAE design.
TopK and JumpReLU SAEs have more features that trigger frequently—on more than 10% of tokens—than Gated SAEs. These high-frequency JumpReLU characteristics are generally less interpretable, which aligns with previous work assessing TopK SAEs; nevertheless, interpretability does improve with increasing SAE sparsity. This means that as the SAE becomes more sparse, the features it learns become more interpretable. Moreover, in a 131k-width SAE, less than 0.06% of the features have extremely high frequencies. Furthermore, the findings of interpretability tests, both manual and automated, show that features selected randomly from JumpReLU, TopK, and Gated SAE are equally interpretable.
This work also assesses a single Gemma 2 9B model that trains SAEs on many sites and layers. The team highlights that since other models may have different architectural or training details, how effectively these results would transfer to others is unclear. Evaluating SAE performance based on principles is a relatively new field of study. It needs to be apparent how well the features of SAEs that make them helpful for downstream purposes connect with the feature interpretability tested (as evaluated by human raters and by Gemini Flash’s ability to anticipate new activations given activating instances).
Compared to Gated SAEs, JumpReLU SAEs, similar to TopK SAEs, contain a higher proportion of high-frequency features. These are defined as features that are active on tokens with a frequency greater than 10%. The team is optimistic about future work with additional adjustments to the loss function utilized to train JumpReLU SAEs. They believe that these adjustments will directly address this issue, offering hope for further advancements in SAE design and leaving the audience hopeful about the future of SAEs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter.. Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
[ad_2]
Source link