Enhancing Deep Learning-Based Neuroimaging Classification with 3D-to-2D Knowledge Distillation
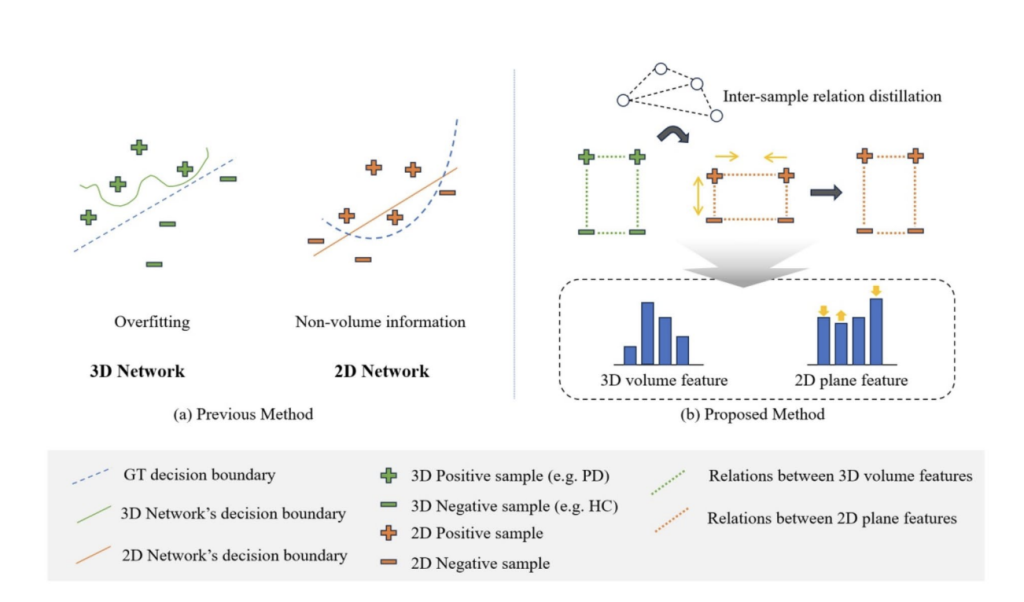
Deep learning techniques are increasingly applied to neuroimaging analysis, with 3D CNNs offering superior performance for volumetric imaging. However, their reliance on large datasets is challenging due to the high cost and effort required for medical data collection and annotation. As an alternative, 2D CNNs utilize 2D projections of 3D images, which often limits volumetric context, affecting diagnostic accuracy. Techniques like transfer learning and knowledge distillation (KD) address these challenges by leveraging pre-trained models and transferring knowledge from complex teacher networks to simpler student models. These approaches enhance performance while maintaining generalizability in resource-constrained medical imaging tasks.
In neuroimaging analysis, 2D projection methods adapt 3D volumetric imaging for 2D CNNs, typically by selecting representative slices. Techniques like Shannon entropy have been used to identify diagnostically relevant slices, while methods like 2D+e enhance information by combining slices. KD, introduced by Hinton, transfers knowledge from complex models to simpler ones. Recent advances include cross-modal KD, where multimodal data enhances monomodal learning, and relation-based KD, which captures inter-sample relationships. However, applying KD to teach 2D CNNs, the volumetric relationships in 3D imaging still need to be explored despite its potential to improve neuroimaging classification with limited data.
Researchers from Dong-A University propose a 3D-to-2D KD framework to enhance 2D CNNs’ ability to learn volumetric information from limited datasets. The framework includes a 3D teacher network encoding volumetric knowledge, a 2D student network focusing on partial volumetric data, and a distillation loss to align feature embeddings between the two. Applied to Parkinson’s disease classification tasks using 123I-DaTscan SPECT and 18F-AV133 PET datasets, the method demonstrated superior performance, achieving a 98.30% F1 score. This projection-agnostic approach bridges the modality gap between 3D and 2D imaging, improving generalizability and addressing challenges in medical imaging analysis.
The method improves the representation of partial volumetric data by leveraging relational information, unlike prior approaches that rely on basic slice extraction or feature combinations without focusing on lesion analysis. We introduce a “partial input restriction” strategy to enhance 3D-to-2D KD. This involves projecting 3D volumetric data into 2D inputs via techniques like single slices, early fusion (channel-level concatenation), joint fusion (intermediate feature aggregation), and rank-pooling-based dynamic images. A 3D teacher network encodes volumetric knowledge using modified ResNet18, and a 2D student network, trained on partial projections, aligns with this knowledge through supervised learning and similarity-based feature alignment.
The study evaluated various 2D projection methods combined with 3D-to-2D KD for performance enhancement. Methods included single-slice inputs, adjacent slices (EF and JF setups), and rank-pooling techniques. Results showed consistent improvements with 3D-to-2D KD, with the JF-based FuseMe setup achieving the best performance, comparable to the 3D teacher model. External validation on the F18-AV133 PET dataset revealed the 2D student network, after KD, outperformed the 3D teacher model. Ablation studies highlighted the superior impact of feature-based loss (Lfg) over logits-based loss (Llg). The framework effectively improved volumetric feature understanding while addressing modality gaps.
In conclusion, the study contrasts the proposed 3D-to-2D KD approach with prior methods in neuroimaging classification, emphasizing its integration of 3D volumetric data. Unlike traditional 2D CNN-based systems, which transform volumetric data into 2D slices, the proposed method trains a 3D teacher network to distill knowledge into a 2D student network. This process reduces computational demands while leveraging volumetric insights for enhanced 2D modeling. The method proves robust across data modalities, as shown in SPECT and PET imaging. Experimental results highlight its ability to generalize from in-distribution to out-of-distribution tasks, significantly improving performance even with limited datasets.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
🎙️ 🚨 ‘Evaluation of Large Language Model Vulnerabilities: A Comparative Analysis of Red Teaming Techniques’ Read the Full Report (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.







