CALM: Credit Assignment with Language Models for Automated Reward Shaping in Reinforcement Learning
[ad_1]
Reinforcement Learning (RL) is a critical area of ML that allows agents to learn from their interactions within an environment by receiving feedback as rewards. A significant challenge in RL is solving the temporal credit assignment problem, which refers to determining which actions in a sequence contributed to achieving a desired outcome. This is particularly difficult when feedback is sparse or delayed, meaning agents don’t immediately know if their actions are correct. In such situations, agents must learn how to correlate specific actions with outcomes, but the lack of immediate feedback makes this a complex task. RL systems often fail to generalize and scale effectively to more complicated tasks without effective mechanisms to resolve this challenge.
The research addresses the difficulty of credit assignment when rewards are delayed and sparse. RL agents often start without prior knowledge of the environment and must navigate through it based solely on trial and error. When feedback is scarce, the agent may struggle to develop a robust decision-making process because it cannot discern which actions led to successful outcomes. This scenario can be particularly challenging in complex environments with multiple steps leading to a goal, where only the final action sequence produces a reward. In many instances, agents end up learning inefficient policies or fail to generalize their behavior across different environments due to this fundamental problem.
Traditionally, RL has relied on techniques like reward shaping and hierarchical reinforcement learning (HRL) to tackle the credit assignment problem. Reward shaping is a method where artificial rewards are added to guide the agent’s behavior when natural rewards are insufficient. In HRL, tasks are broken down into simpler sub-tasks or options, with agents being trained to achieve intermediate goals. While both techniques can be effective, they require significant domain knowledge and human input, making them difficult to scale. In recent years, large language models (LLMs) have demonstrated potential in transferring human knowledge into computational systems, offering new ways to improve the credit assignment process without excessive human intervention.
The research team from University College London, Google DeepMind, and the University of Oxford developed a new approach called Credit Assignment with Language Models (CALM). CALM leverages the power of LLMs to decompose tasks into smaller subgoals and assess the agent’s progress toward these goals. Unlike traditional methods that require extensive human-designed rewards, CALM automates this process by allowing the LLM to determine subgoals and provide auxiliary reward signals. The technique reduces human involvement in designing RL systems, making it easier to scale to different environments. Researchers claim that this method can handle zero-shot settings, meaning the LLM can evaluate actions without requiring fine-tuning or prior examples specific to the task.
CALM uses LLMs to assess whether specific subgoals are achieved during a task. For instance, in the MiniHack environment used in the study, agents are tasked with picking up a key and unlocking a door to receive a reward. CALM breaks down this task into manageable subgoals, such as “navigate to the key,” “pick up the key,” and “unlock the door.” Each time one of these subgoals is completed, CALM provides an auxiliary reward to the RL agent, guiding it toward completing the final task. This system reduces the need for manually designed reward functions, which are often time-consuming and domain-specific. Instead, the LLM uses its prior knowledge to effectively shape the agent’s behavior.
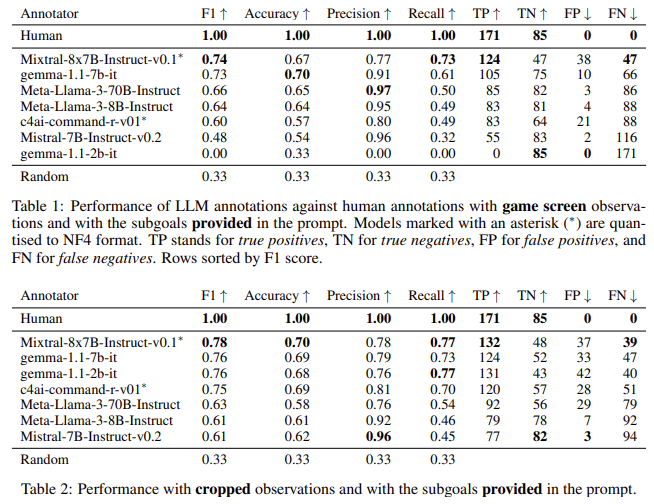
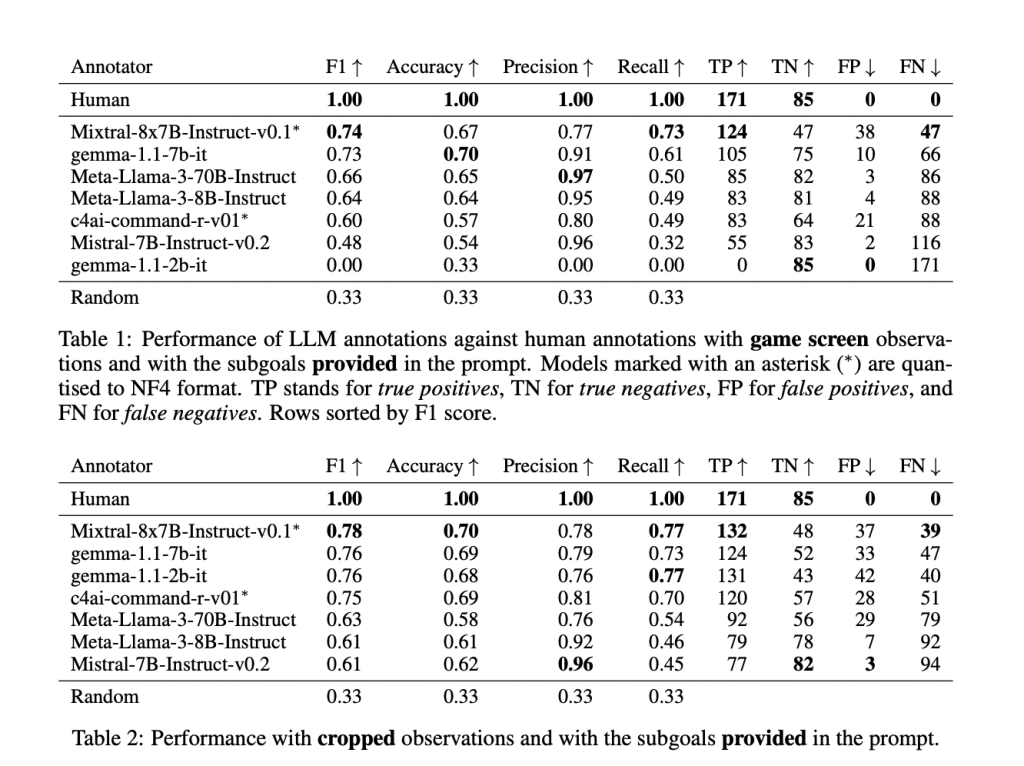
The researchers’ experiments evaluated CALM using a dataset of 256 human-annotated demonstrations from MiniHack, a gaming environment that challenges agents to solve tasks in a grid-like world. The results showed that LLMs could successfully assign credit in zero-shot settings, meaning the model did not require prior examples or fine-tuning. In particular, the LLM could recognize when subgoals had been achieved, providing useful guidance to the RL agent. The study found that the LLM accurately recognized subgoals and aligned them with human annotations, achieving an F1 score of 0.74. The LLM’s performance improved significantly when using more focused observations, such as cropped images showing a 9×9 view around the agent. This suggests that LLMs can be a valuable tool in automating credit assignment, particularly in environments where natural rewards are sparse or delayed.
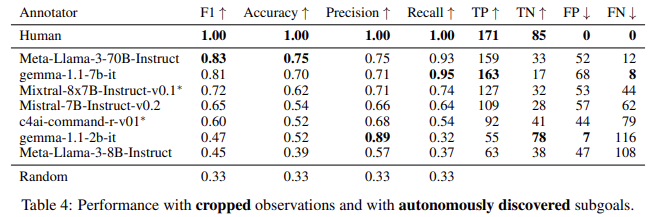
The researchers also reported that CALM’s performance was competitive with that of human annotators in identifying successful subgoal completions. In some cases, the LLM achieved an accuracy rate of 0.73 in detecting when an agent had completed a subgoal, and the auxiliary rewards provided by CALM helped the agent learn more efficiently. The team also compared the performance of CALM to existing models like Meta-Llama-3 and found that CALM performed well across various metrics, including recall and precision, with precision scores ranging from 0.60 to 0.97, depending on the model and task.

In conclusion, the research demonstrates that CALM can effectively tackle the credit assignment problem in RL by leveraging LLMs. CALM reduces the need for extensive human involvement in designing RL systems by breaking tasks into subgoals and automating reward shaping. The experiments indicate that LLMs can provide accurate feedback to RL agents, improving their learning ability in environments with sparse rewards. This approach can enhance RL performance in various applications, making it a promising avenue for future research and development. The study highlights the potential for LLMs to generalize across tasks, making RL systems more scalable and efficient in real-world scenarios.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
⏩ ⏩ FREE AI WEBINAR: ‘SAM 2 for Video: How to Fine-tune On Your Data’ (Wed, Sep 25, 4:00 AM – 4:45 AM EST)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
[ad_2]
Source link