Apple Researchers Present KGLens: A Novel AI Method Tailored for Visualizing and Evaluating the Factual Knowledge Embedded in LLMs
[ad_1]
Large Language Models (LLMs) have gained significant attention for their versatility, but their factualness remains a critical concern. Studies have revealed that LLMs can produce nonfactual, hallucinated, or outdated information, undermining reliability. Current evaluation methods, such as fact-checking and fact-QA, face several challenges. Fact-checking struggles to assess the factualness of generated content, while fact-QA encounters difficulties scaling up evaluation data due to expensive annotation processes. Both approaches also face the risk of data contamination from web-crawled pretraining corpora. Also, LLMs often respond inconsistently to the same fact when presented in different forms, a challenge is that existing evaluation datasets need to be equipped to address.
Existing attempts to evaluate LLMs’ knowledge primarily use specific datasets, but face challenges like data leakage, static content, and limited metrics. Knowledge graphs (KGs) offer advantages in customization, evolving knowledge, and reduced test set leakage. Methods like LAMA and LPAQA use KGs for evaluation but struggle with unnatural question formats and impracticality for large KGs. KaRR overcomes some issues but remains inefficient for large graphs and lacks generalizability. Current approaches focus on accuracy over reliability, failing to address LLMs’ inconsistent responses to the same fact. Also, no existing work visualizes LLMs’ knowledge using KGs, presenting an opportunity for improvement. These limitations highlight the need for more comprehensive and efficient methods to evaluate and understand LLMs’ knowledge retention and accuracy.
Researchers from Apple introduced KGLENS, an innovative knowledge probing framework that has been developed to measure knowledge alignment between KGs and LLMs and identify LLMs’ knowledge blind spots. The framework employs a Thompson sampling-inspired method with a parameterized knowledge graph (PKG) to probe LLMs efficiently. KGLENS features a graph-guided question generator that converts KGs into natural language using GPT-4, designing two types of questions (fact-checking and fact-QA) to reduce answer ambiguity. Human evaluation shows that 97.7% of generated questions are sensible to annotators.
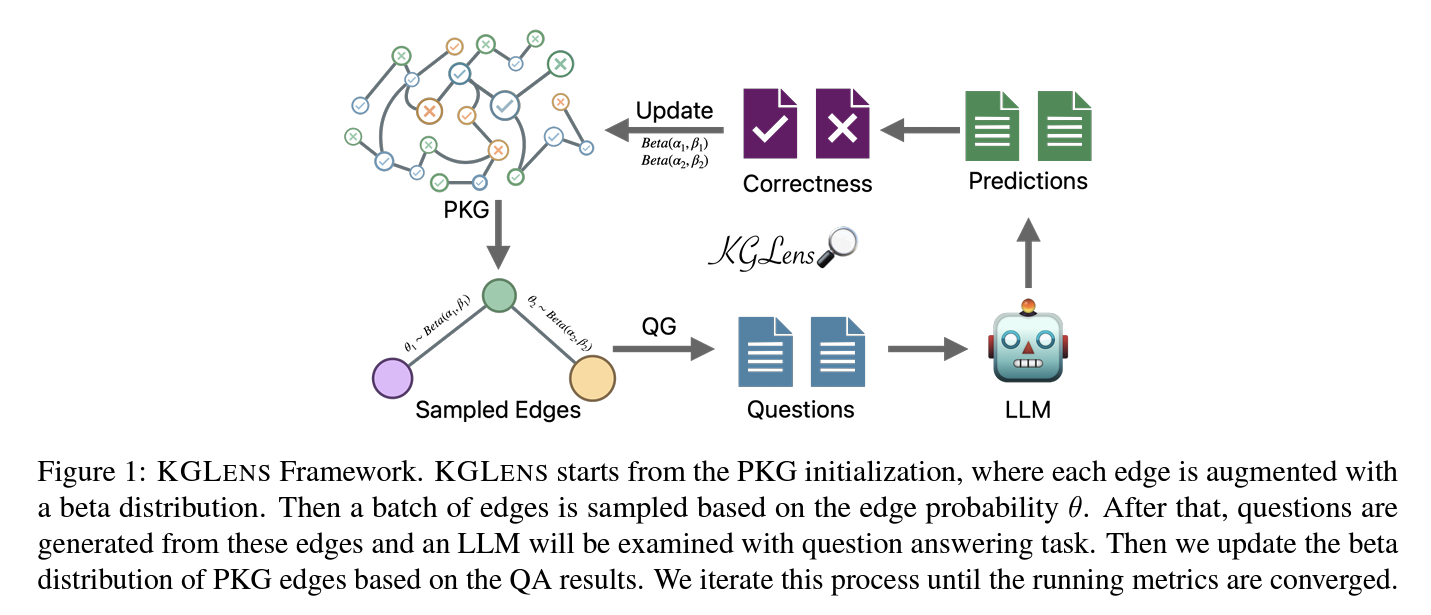
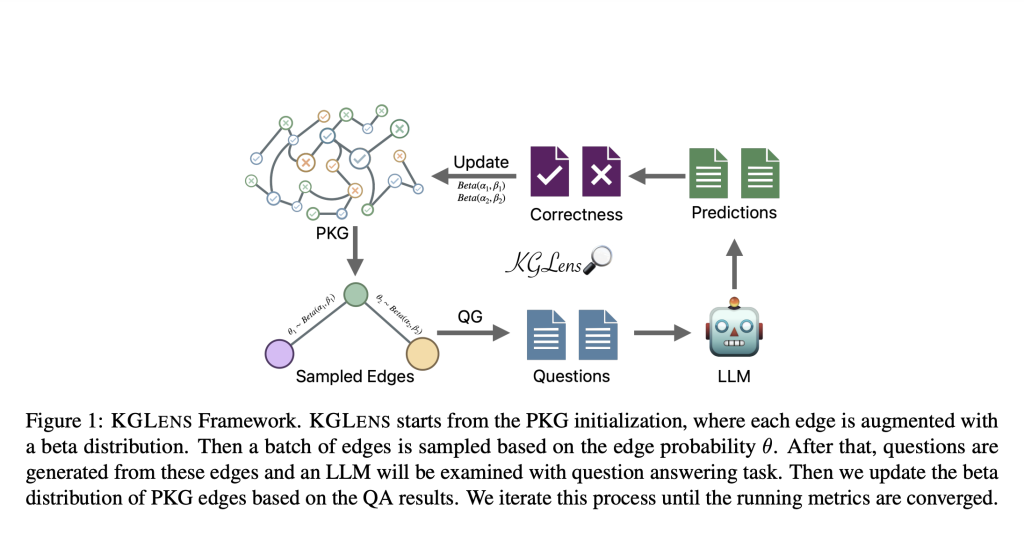
KGLENS employs a unique approach to efficiently probe LLMs’ knowledge using a PKG and Thompson sampling-inspired method. The framework initializes a PKG where each edge is augmented with a beta distribution, indicating the LLM’s potential deficiency on that edge. It then samples edges based on their probability, generates questions from these edges, and examines the LLM through a question-answering task. The PKG is updated based on the results, and this process iterates until convergence. Also, This framework features a graph-guided question generator that converts KG edges into natural language questions using GPT-4. It creates two types of questions: Yes/No questions for judgment and Wh-questions for generation, with the question type controlled by the graph structure. Entity aliases are included to reduce ambiguity.
For answer verification, KGLENS instructs LLMs to generate specific response formats and employs GPT-4 to check the correctness of responses for Wh-questions. The framework’s efficiency is evaluated through various sampling methods, demonstrating its effectiveness in identifying LLMs’ knowledge blind spots across diverse topics and relationships.
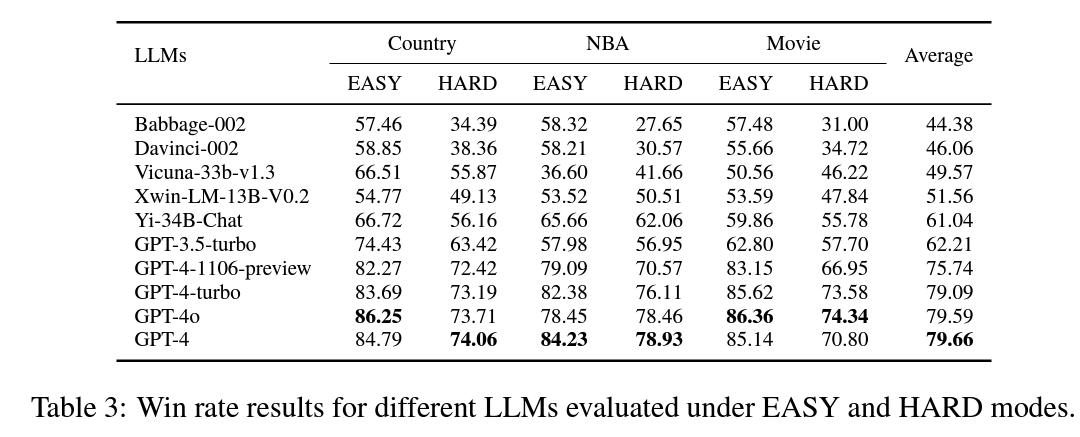
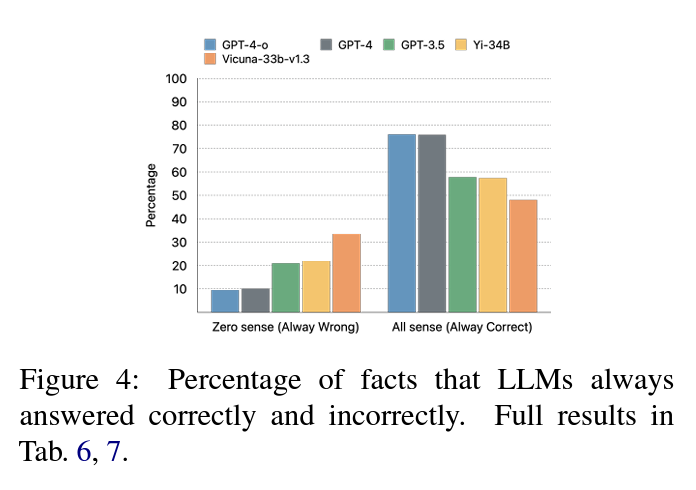
KGLENS evaluation across various LLMs reveals that the GPT-4 family consistently outperforms other models. GPT-4, GPT-4o, and GPT-4-turbo show comparable performance, with GPT-4o being more cautious with personal information. A significant gap exists between GPT-3.5-turbo and GPT-4, with GPT-3.5-turbo sometimes performing worse than legacy LLMs due to its conservative approach. Legacy models like Babbage-002 and Davinci-002 show only slight improvement over random guessing, highlighting the progress in recent LLMs. The evaluation provides insights into different error types and model behaviors, demonstrating the varying capabilities of LLMs in handling diverse knowledge domains and difficulty levels.
KGLENS introduces an efficient method for evaluating factual knowledge in LLMs using a Thompson sampling-inspired approach with parameterized Knowledge Graphs. The framework outperforms existing methods in revealing knowledge blind spots and demonstrates adaptability across various domains. Human evaluation confirms its effectiveness, achieving 95.7% accuracy. KGLENS and its assessment of KGs will be made available to the research community, fostering collaboration. For businesses, this tool facilitates the development of more reliable AI systems, enhancing user experiences and improving model knowledge. KGLENS represents a significant advancement in creating more accurate and dependable AI applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
[ad_2]
Source link