OpenAI Releases SimpleQA: A New AI Benchmark that Measures the Factuality of Language Models
The rise of large language models has been accompanied by significant challenges, particularly around ensuring the factuality of generated responses. One persistent issue is that these models can produce outputs that are factually incorrect or even misleading, a phenomenon often called “hallucination.” These hallucinations occur when models generate confident-sounding but incorrect or unverifiable information. Given the growing reliance on AI for information, factual accuracy has become critical. However, evaluating this accuracy is not easy, especially for long-form completions filled with multiple factual claims.
OpenAI recently open-sourced SimpleQA: a new benchmark that measures the factuality of responses generated by language models. SimpleQA is unique in its focus on short, fact-seeking questions with a single, indisputable answer, making it easier to evaluate the factual correctness of model responses. Unlike other benchmarks that often become outdated or saturated over time, SimpleQA was designed to remain challenging for the latest AI models. The questions in SimpleQA were created in an adversarial manner against responses from GPT-4, ensuring that even the most advanced language models struggle to answer them correctly. The benchmark contains 4,326 questions spanning various domains, including history, science, technology, art, and entertainment, and is built to be highly evaluative of both model precision and calibration.
SimpleQA’s design follows specific principles to ensure it serves as a robust factuality benchmark. First, questions are created with high correctness in mind: each question has a reference answer determined by two independent AI trainers to ensure consistency. The dataset was curated to focus only on questions that can be answered with a single, clear response, which prevents ambiguity and makes grading simpler. Moreover, grading is carried out by a prompted ChatGPT classifier, which assesses responses as either “correct,” “incorrect,” or “not attempted.” This straightforward structure allows researchers to assess how models perform under factual constraints.
The diversity of questions is another key benefit of SimpleQA. It features a broad set of topics to prevent model specialization and ensure a holistic evaluation. Moreover, the dataset’s usability is enhanced by its simplicity—both questions and answers are short, which makes the benchmark fast to run and reduces variance during evaluation runs. Importantly, SimpleQA also incorporates questions that have been verified to be relevant over time, thus eliminating the influence of shifting information and making it an “evergreen” benchmark.
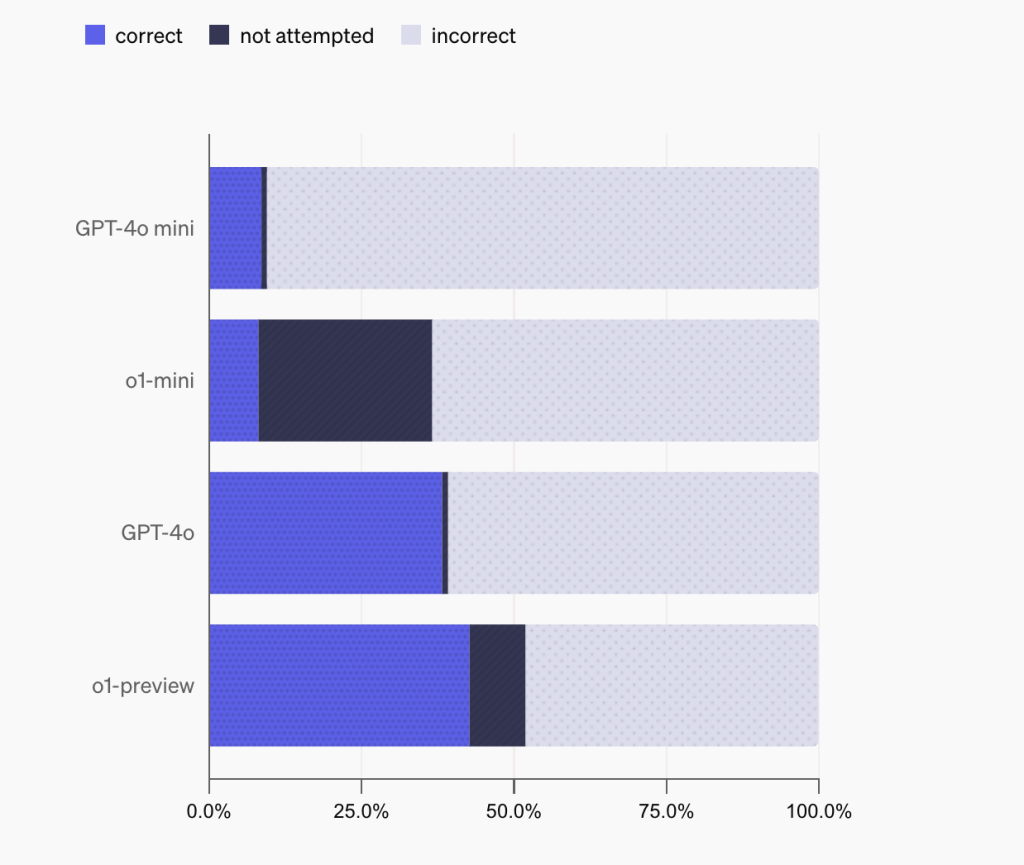
The importance of SimpleQA lies in its targeted evaluation of language models’ factual abilities. In a landscape where many benchmarks have been “solved” by recent models, SimpleQA is designed to remain challenging even for frontier models like GPT-4 and Claude. For instance, models such as GPT-4o scored only about 38.4% in terms of correct answers, highlighting the benchmark’s ability to probe areas where even advanced models face difficulties. Other models, including Claude-3.5, performed similarly or worse, indicating that SimpleQA poses a consistent challenge across model types. This benchmark, therefore, provides valuable insights into the calibration and reliability of language models—particularly their ability to discern when they have enough information to answer confidently and correctly.

Moreover, SimpleQA’s grading metrics provide nuanced insights into model behavior. The benchmark calculates not only the percentage of questions answered correctly but also measures “correct given attempted,” a metric akin to precision. These two metrics are combined to derive an F-score, which offers a single-number measure of factuality. Notably, the results of SimpleQA suggest that language models tend to overstate their confidence, with a large number of incorrect attempts. The analysis reveals that while larger models demonstrate better calibration (meaning they are better at recognizing when they know the correct answer), the overall accuracy leaves room for improvement.
SimpleQA is an important step toward improving the reliability of AI-generated information. By focusing on short, fact-based questions, it provides a practical, easy-to-use benchmark that helps evaluate a critical aspect of language models: their ability to generate factual content consistently. Given the benchmark’s adversarial design, SimpleQA sets a high bar for accuracy, encouraging researchers and developers to create models that not only generate language but do so truthfully. The open sourcing of SimpleQA provides the AI community with a valuable tool for assessing and improving the factual accuracy of language models, helping to ensure that future AI systems can be both informative and trustworthy.
Check out the Paper, Details, and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.








