Self-Training on Image Comprehension (STIC): A Novel Self-Training Approach Designed to Enhance the Image Comprehension Capabilities of Large Vision Language Models (LVLMs)
Large language models (LLMs) have gained significant attention due to their advanced capabilities in processing and generating text. However, the increasing demand for multimodal input processing has led to the development of vision language models. These models combine the strengths of LLMs with image encoders to create large vision language models (LVLMs). Despite their promising results, LVLMs face a significant challenge in acquiring high-quality fine-tuning data, because obtaining human-curated content at scale is often prohibitively expensive, especially for multi-modal data. So, there is an urgent need for cost-effective methods to obtain fine-tuning data to enhance LVLMs and expand their capabilities.
Recent advancements in VLMs have been driven by integrating open-source LLMs with innovative image encoders, leading to the development of LVLMs. Examples include LLaVA, which combines CLIP’s vision encoder with the Vicuna LLM, and other models like LLaMA-Adapter-V2, Qwen-VL, and InternVL. However, they often depend on expensive human-curated or AI-generated data for fine-tuning. Recent research has addressed this limitation by exploring alignment fine-tuning techniques, such as direct policy optimization (DPO) and iterative preference fine-tuning. However, adapting these techniques for LVLMs has been limited, with initial attempts focusing on human-labeled data or GPT-4 generated content for fine-tuning.
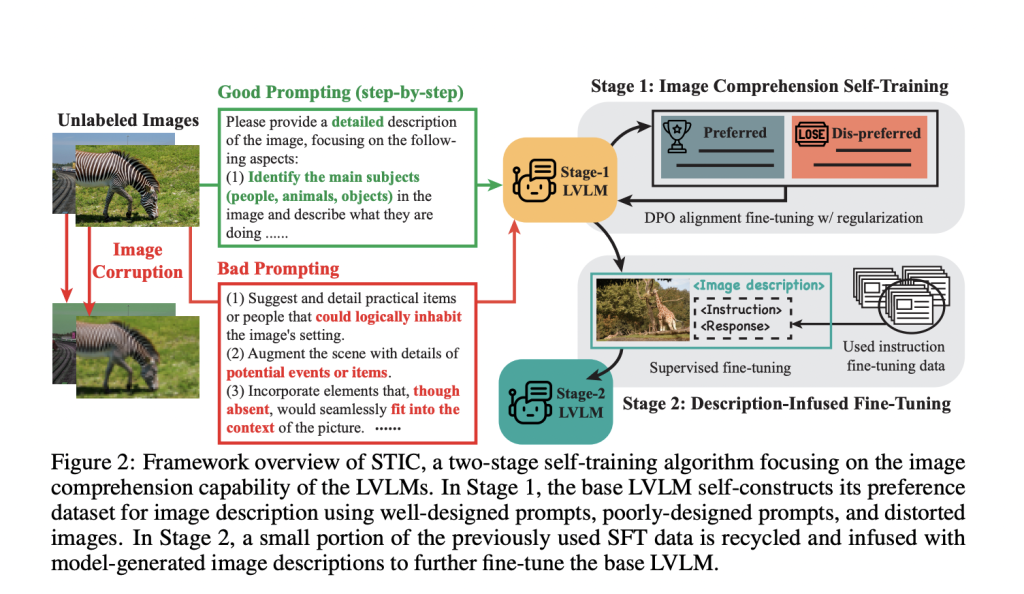
Researchers from UCLA, UC Berkeley, and Stanford University have introduced an approach called Self-Training on Image Comprehension (STIC). This method emphasizes self-training specifically for image comprehension in LVLMs and self-constructs a preference dataset for image descriptions using unlabeled images. It generates preferred responses through a step-by-step prompt and dis-preferred responses from corrupted images or misleading prompts. STIC reuses a small portion of existing instruction-tuning data and appends self-generated image descriptions to the prompts to enhance reasoning on extracted visual information.
The STIC method utilizes llava-v1.6-mistral-7b as the base model for self-training with model-generated preference data. The process involves two main stages: self-training on image description (Algorithm 1) and description-infused fine-tuning (Algorithm 2). For the self-constructed preference dataset, 6,000 unlabeled images are randomly sampled from the MSCOCO dataset’s train2014 split. The second stage involves randomly subsampling 5,000 instruction fine-tuning data points from LLaVA’s SFT data to construct description-infused fine-tuning data. It uses a low-rank adaptation (LoRA) fine-tuning for efficient computation. The performance of STIC is evaluated based on seven benchmarks including ScienceQA, TextVQA, ChartQA, LLaVA-Bench, MMBench, MM-Vet, and MathVista.
The STIC method demonstrates consistent and significant improvements over the original LLaVA models across seven diverse datasets. It enhances LLaVA-v1.5’s performance by an average of 1.7% and LLaVA-v1.6’s performance by 4.0%. These improvements are achieved using only self-constructed preference data and a small portion of the model’s original fine-tuning dataset. The more advanced LLaVA-v1.6 model shows more improvement than LLaVA-v1.5, indicating a potential correlation between a model’s inherent capabilities and its capacity for self-improvement through STIC. Researchers also conducted ablation studies on the key components of STIC to demonstrate their importance and effectiveness and examined the image distribution of self-training data (MSCOCO).
In this paper, researchers have proposed Self-Training on Image Comprehension (STIC) to enhance the image comprehension capabilities of LVLMs. They conducted experiments across seven vision-language benchmarks that demonstrated significant performance improvements. The results highlight STIC’s potential to utilize vast quantities of unlabeled images, offering a cost-effective solution for advancing LVLMs. Future research could focus on testing STIC with larger models, studying how image distribution affects the success of self-training, and exploring how different image corruptions and prompts influence the creation of less desirable samples. These efforts might improve STIC’s performance and expand its role in advancing LVLM development.
Check out the Paper, GitHub, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.









