ARCLE: A Reinforcement Learning Environment for Abstract Reasoning Challenges
[ad_1]
Reinforcement learning (RL) is a specialized branch of artificial intelligence that trains agents to make sequential decisions by rewarding them for performing desirable actions. This technique is extensively applied in robotics, gaming, and autonomous systems, allowing machines to develop complex behaviors through trial and error. RL enables agents to learn from their interactions with the environment, adjusting their actions based on feedback to maximize cumulative rewards over time.
One of the significant challenges in RL is addressing tasks that require high levels of abstraction and reasoning, such as those presented by the Abstraction and Reasoning Corpus (ARC). The ARC benchmark, designed to test the abstract reasoning abilities of AI, poses a unique set of difficulties. It features a vast action space where agents must perform a variety of pixel-level manipulations, making it hard to develop optimal strategies. Furthermore, defining success in ARC is non-trivial, requiring accurately replicating complex grid patterns rather than reaching a physical location or endpoint. This complexity necessitates a deep understanding of task rules and precise application, complicating the reward system design.
Traditional approaches to ARC have primarily focused on program synthesis and leveraging large language models (LLMs). While these methods have advanced the field, they often need to catch up due to the logical complexities involved in ARC tasks. The performance of these models has yet to meet expectations, leading researchers to explore alternative approaches fully. Reinforcement learning has emerged as a promising yet underexplored method for tackling ARC, offering a new perspective on addressing its unique challenges.
Researchers from the Gwangju Institute of Science and Technology and Korea University have introduced ARCLE (ARC Learning Environment) to address these challenges. ARCLE is a specialized RL environment designed to facilitate research on ARC. It was developed using the Gymnasium framework, providing a structured platform where RL agents can interact with ARC tasks. This environment enables researchers to train agents using reinforcement learning techniques specifically tailored for the complex tasks presented by ARC.
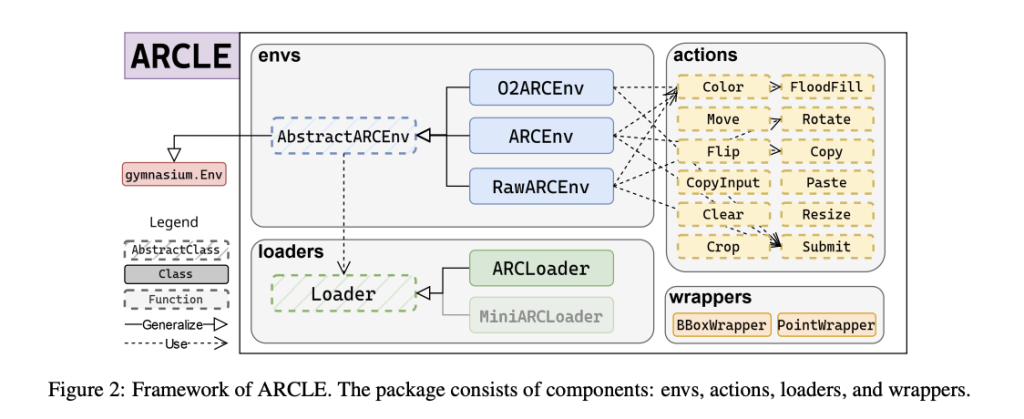
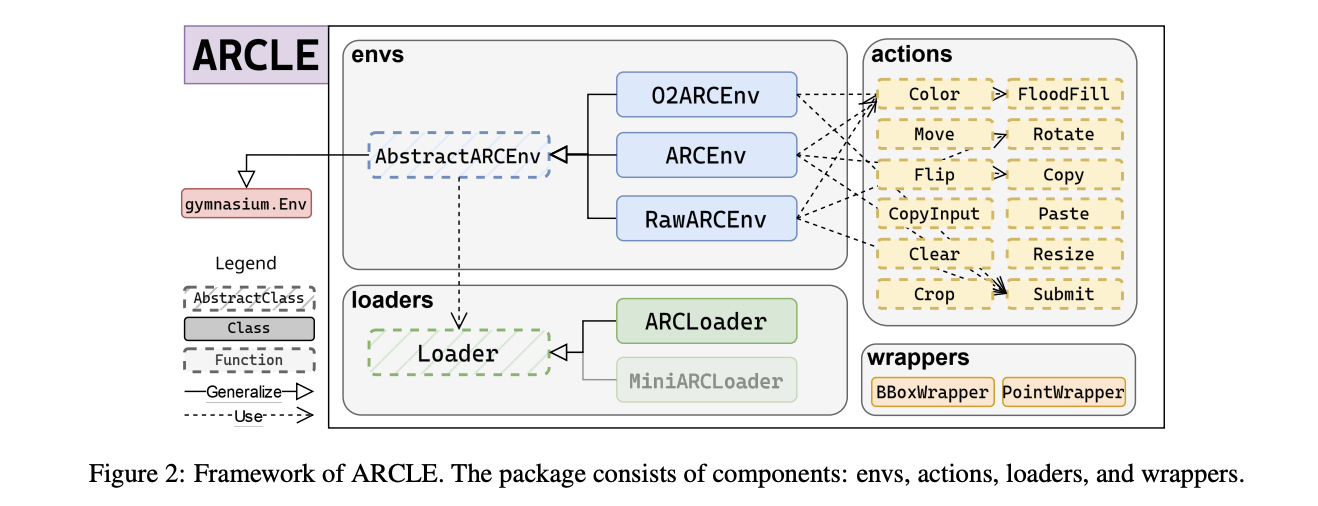
ARCLE comprises several key components: environments, loaders, actions, and wrappers. The environment component includes a base class and its derivatives, which define the structure of action and state spaces and user-definable methods. The loaders component supplies the ARC dataset to ARCLE environments, defining how datasets should be parsed and sampled. Actions in ARCLE are defined to enable various grid manipulations, such as coloring, moving, and rotating pixels. These actions are designed to reflect the types of manipulations required to solve ARC tasks. The wrappers component modifies the environment’s action or state space, enhancing the learning process by providing additional functionalities.
The research demonstrated that RL agents trained within ARCLE using proximal policy optimization (PPO) could successfully learn individual tasks. The introduction of non-factorial policies and auxiliary losses significantly improved performance. These enhancements effectively mitigated issues related to navigating the vast action space and achieving the hard-to-reach goals of ARC tasks. The research highlighted that agents equipped with these advanced techniques showed marked improvements in task performance. For instance, the PPO-based agents achieved a high success rate in solving ARC tasks when trained with auxiliary loss functions that predicted previous rewards, current rewards, and next states. This multi-faceted approach helped the agents learn more effectively by providing additional guidance during training.
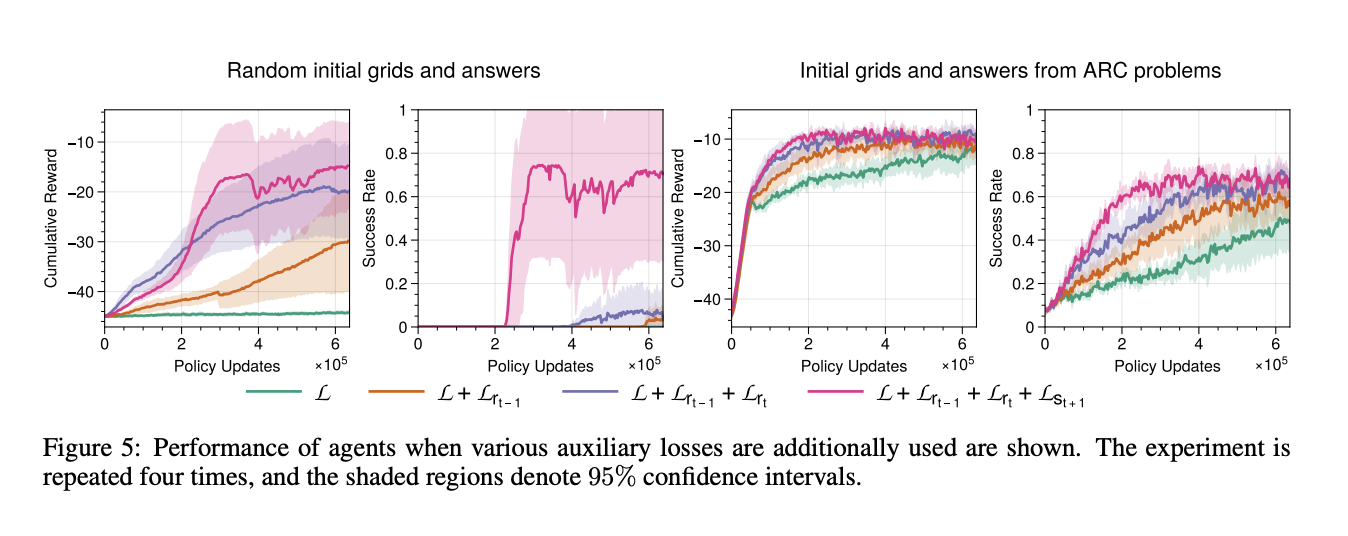
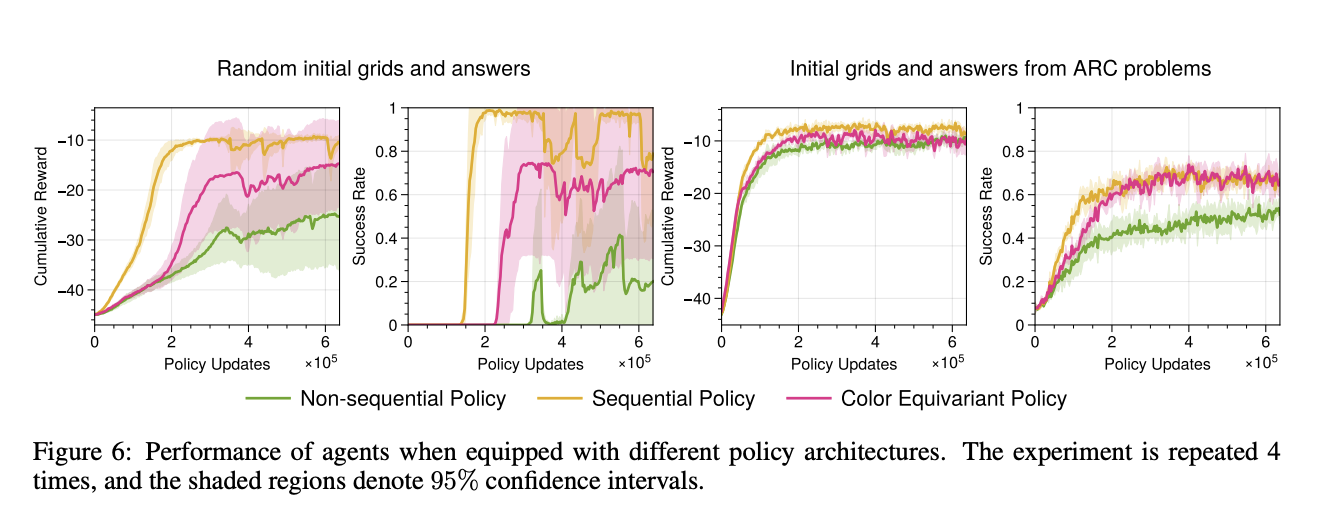
Agents trained with proximal policy optimization (PPO) and enhanced with non-factorial policies and auxiliary losses achieved a success rate exceeding 95% in random settings. The introduction of auxiliary losses, which included predicting previous rewards, current rewards, and next states, led to a marked increase in cumulative rewards and success rates. Performance metrics showed that agents trained with these methods outperformed those without auxiliary losses, achieving a 20-30% higher success rate in complex ARC tasks.
To conclude, the research underscores the potential of ARCLE in advancing RL strategies for abstract reasoning tasks. By creating a dedicated RL environment tailored to ARC, the researchers have paved the way for exploring advanced RL techniques such as meta-RL, generative models, and model-based RL. These methodologies promise to enhance AI’s reasoning and abstraction capabilities further, driving progress in the field. The integration of ARCLE into RL research addresses the current challenges of ARC and contributes to the broader endeavor of developing AI that can learn, reason, and abstract effectively. This research invites the RL community to engage with ARCLE and explore its potential for advancing AI research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.

[ad_2]
Source link







