ColPali: A Novel AI Model Architecture and Training Strategy based on Vision Language Models (VLMs) to Efficiently Index Documents Purely from Their Visual Features
[ad_1]
Document retrieval, a subfield of information retrieval, focuses on matching user queries with relevant documents within a corpus. It is crucial in various industrial applications, such as search engines and information extraction systems. Effective document retrieval systems must handle textual content and visual elements like images, tables, and figures to convey information to users efficiently.
Modern document retrieval systems often need help in efficiently exploiting visual cues, which limits their performance. These systems primarily focus on text-based matching, which hampers their ability to handle visually rich documents effectively. The key issue is integrating visual information with text to enhance retrieval accuracy and efficiency. This is particularly challenging because visual elements often convey critical information that text alone cannot capture.
Traditional methods such as TF-IDF and BM25 rely on word frequency and statistical measures for text retrieval. Neural embedding models have improved retrieval performance by encoding documents into dense vector spaces. However, these methods often need to pay more attention to visual elements, leading to suboptimal results for documents rich in visual content. Recent advancements in late interaction mechanisms and vision-language models have shown potential, but their effectiveness in practical applications still needs to be improved.
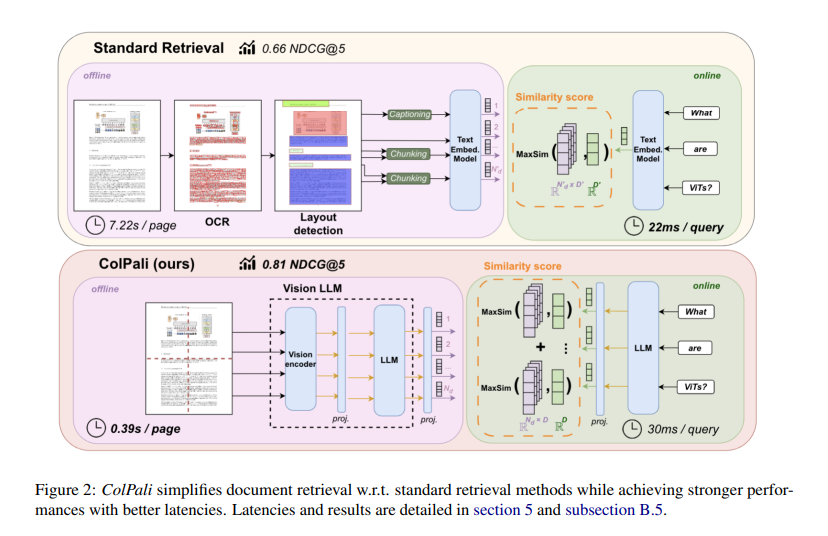
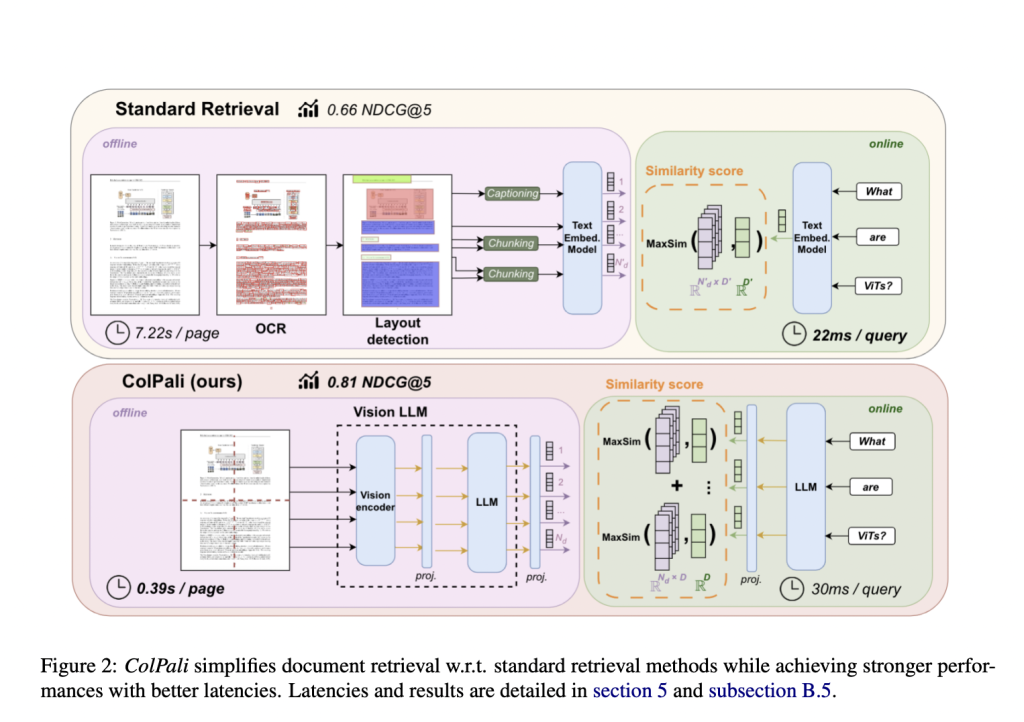
Researchers from Illuin Technology, Equall.ai, CentraleSupélec, Paris-Saclay, and ETH Zürich have introduced a novel model architecture called ColPali. This model leverages recent Vision Language Models (VLMs) to create high-quality contextualized embeddings from document images. ColPali aims to outperform existing document retrieval systems by effectively integrating visual and textual features. The model processes images of document pages to generate embeddings, enabling fast and accurate query matching. This approach addresses the inherent limitations of traditional text-centric retrieval methods.
ColPali uses the ViDoRe benchmark, including datasets such as DocVQA, InfoVQA, and TabFQuAD. The model uses a late interaction matching mechanism, combining visual understanding with efficient retrieval. ColPali processes images to generate embeddings, integrating visual and textual features. The framework includes creating embeddings from document pages and performing fast query matching, ensuring efficient integration of visual cues into the retrieval process. This method allows for detailed matching between query and document images, enhancing retrieval accuracy.
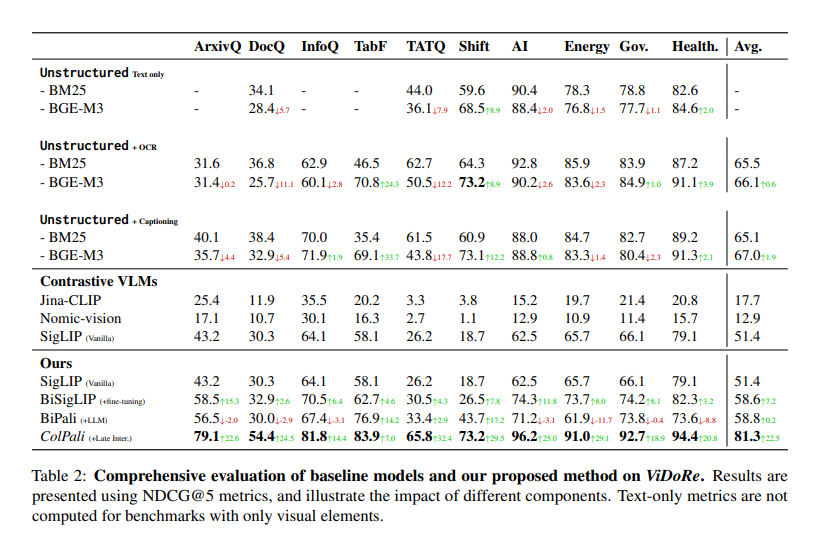
The performance of ColPali significantly surpasses existing retrieval pipelines. The researchers conducted extensive experiments to benchmark ColPali against current systems, highlighting its superior performance. ColPali demonstrated a retrieval accuracy of 90.4% on the DocVQA dataset, significantly outperforming other models. Furthermore, it achieved high scores on various other benchmarks, including 78.8% on TabFQuAD and 82.6% on InfoVQA. These results underscore ColPali‘s capability to handle visually complex documents and diverse languages effectively. The model also exhibited low latency, making it suitable for real-time applications.
In conclusion, the researchers effectively addressed the critical problem of integrating visual and textual features in document retrieval. ColPali offers a robust solution by leveraging advanced vision-language models, significantly enhancing retrieval accuracy and efficiency. This development marks a significant step forward in document retrieval, providing a powerful tool for handling visually rich documents. The success of ColPali underscores the importance of incorporating visual elements into retrieval systems, paving the way for future advancements in this domain.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
[ad_2]
Source link